Latest Announcements

Deepseek OCR: Vision‑Language Compression Meets Dynamic OCR
Published on 2025-11-19


More News





Trending Models

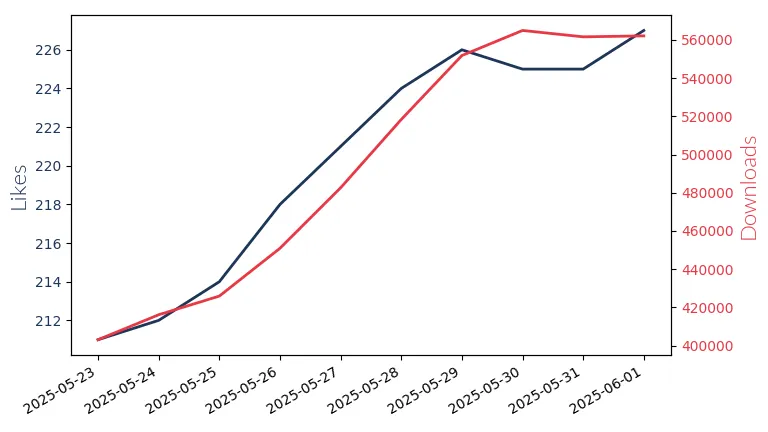
Gpt Oss 120B
GPT-OSS 120B by OpenAI: 120 billion param. model for complex reasoning tasks, supports English only.
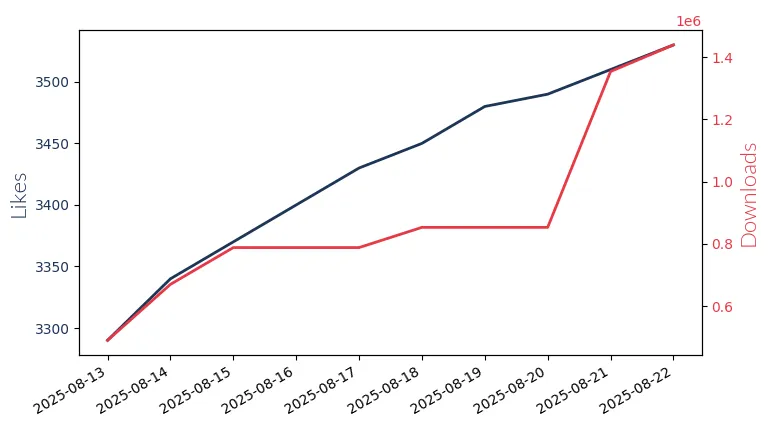
Gpt Oss 20B
GPT-OSS 20B: OpenAI's 20 billion parameter model for low-latency, local applications. Mono-linguistic.
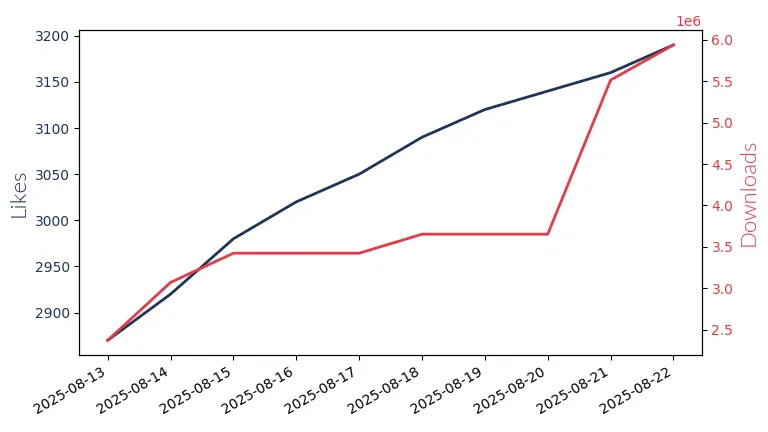

Qwen3 8B
Qwen3 8B: Alibaba's 8 billion parameter LLM for reasoning & problem-solving. Mono-lingual model with context lengths up to 8k.
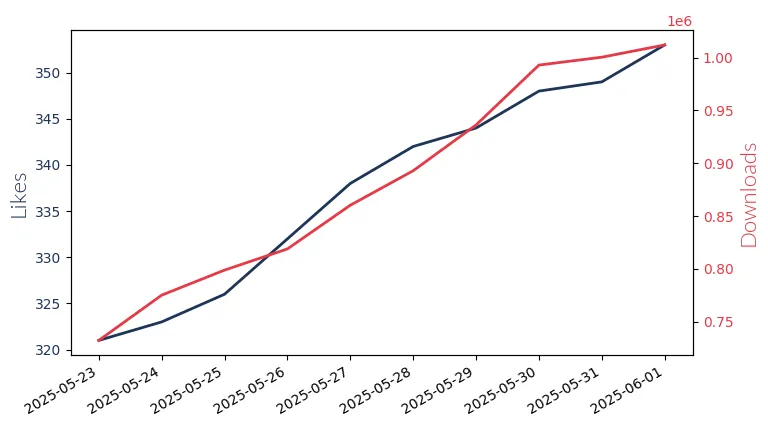

Llama3.2 1B Instruct
Llama3.2 1B Instruct by Meta Llama Enterprise: A versatile, multilingual large language model with 1 billion parameters and context lengths up to 128k, designed for assistant-like chat applications.


Qwen3 Coder 30B
Qwen3 Coder 30B: Alibaba's 30 billion param LLM for agentic coding, supports mono-lingual contexts up to 2,5,6,k.
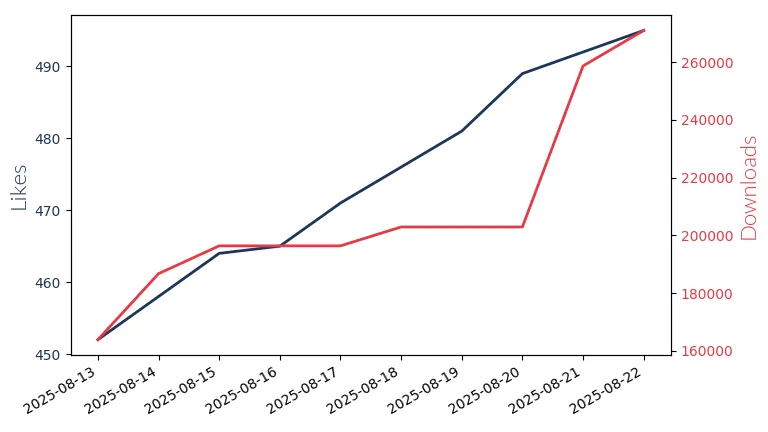
Llama3.2 1B
Llama3.2 1B: Meta's 1B param model for multilingual chat apps, with context lengths up to 128k.

Qwen3 0.6B
Qwen3 0.6B: Alibaba's 0.6 billion param model excels in reasoning tasks with a 32k context window.
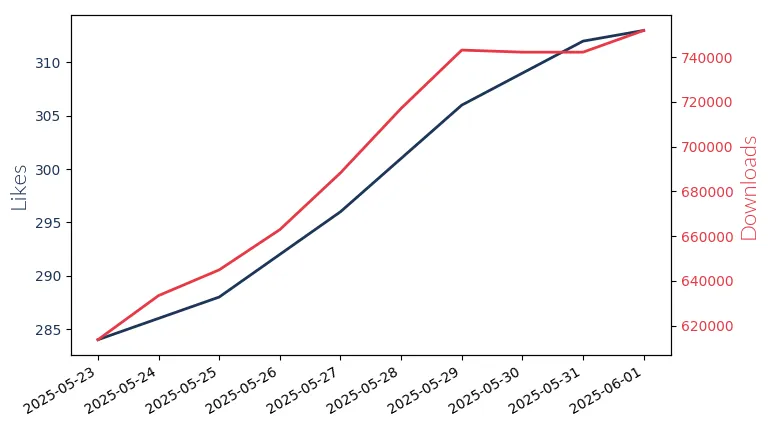

Deepseek R1 671B
Deepseek R1 671B: Bi-lingual Large Language Model with 671 billion parameters. Supports context lengths up to 128k for advanced code generation and debugging tasks.
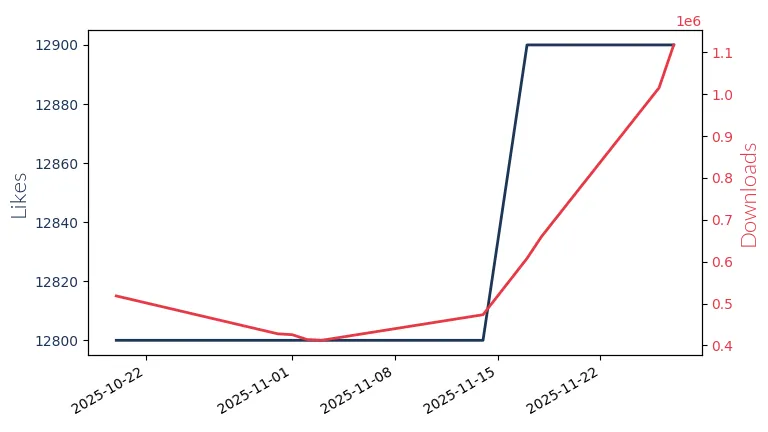

Qwen2.5 Coder 32B Instruct
Qwen2.5 Coder 32B Instruct by Alibaba Qwen: 32 billion param, bilingual, excels in coding tasks.


Qwen2.5Vl 7B
Qwen2.5VL 7B: Alibaba's 7 billion parameter LLM for visual content analysis.
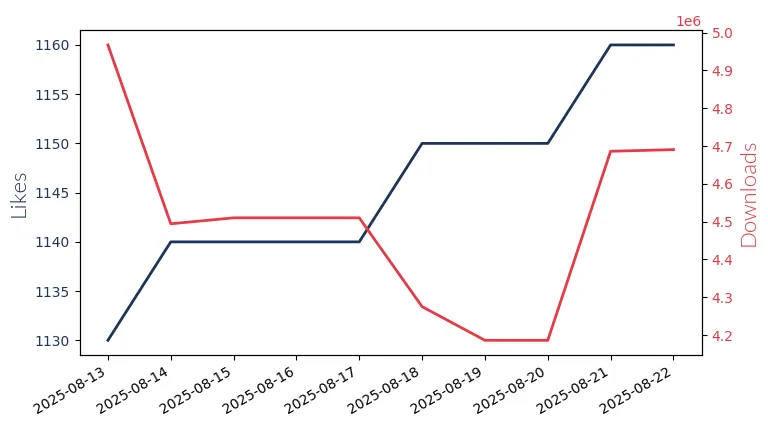

Llama4 109B Instruct
Llama4 109B Instruct by Meta Llama Enterprise: A powerful, multi-lingual large language model with 109 billion parameters, designed for commercial applications.
Qwen3 4B
Qwen3 4B: Alibaba's 4 billion parameter LLM for enhanced reasoning & logic tasks.