Deepseek R1 32B - Model Details

Deepseek R1 32B is a large language model developed by Deepseek, a company, featuring 32 billion parameters. It operates under the MIT License, ensuring open access and flexibility for users. The model emphasizes enhancing reasoning capabilities through reinforcement learning, avoiding supervised fine-tuning to prioritize autonomous learning and adaptability.
Description of Deepseek R1 32B
DeepSeek-R1 is a large-scale reasoning model developed using reinforcement learning (RL) without supervised fine-tuning (SFT). It addresses limitations of its predecessor, DeepSeek-R1-Zero, by incorporating cold-start data, improving issues like endless repetition and poor readability. The model achieves performance comparable to OpenAI-o1 in math, code, and reasoning tasks. It supports distillation into smaller models for efficient deployment while maintaining high performance on benchmarks. The model is open-sourced for research purposes, with variants available for different parameter sizes and base models.
Parameters & Context Length of Deepseek R1 32B
DeepSeek R1 32B features 32 billion parameters, placing it in the large model category, which balances power for complex tasks with resource demands. Its 128k token context length enables handling extensive text sequences, ideal for long-form reasoning but requiring significant computational resources. The model’s parameter size allows advanced reasoning capabilities, while the extended context length supports tasks like analyzing lengthy documents or multi-step problem-solving, though both aspects necessitate robust infrastructure.
- Parameter Size: 32b (Large models for complex tasks, resource-intensive)
- Context Length: 128k (Very long contexts for extended text, highly resource-demanding)
Possible Intended Uses of Deepseek R1 32B
DeepSeek R1 32B is a large language model designed for advanced reasoning tasks, with possible applications in research, code generation, and mathematical problem solving. Its 32 billion parameters and 128k token context length suggest it could support possible uses such as analyzing complex datasets, automating code development, or tackling intricate mathematical challenges. However, these possible scenarios require thorough investigation to confirm their feasibility and effectiveness. The model’s open-source nature allows researchers to explore possible implementations in diverse fields, though careful evaluation is necessary to ensure alignment with specific goals.
- Research
- Code generation
- Mathematical problem solving
Possible Applications of Deepseek R1 32B
DeepSeek R1 32B is a large-scale language model with possible applications in areas such as advanced research, code development, mathematical problem-solving, and handling extended text analysis. Its 32 billion parameters and 128k token context length suggest possible uses for tasks requiring deep reasoning or processing of lengthy documents, though these possible scenarios must be thoroughly evaluated to ensure alignment with specific needs. Possible applications could include automating complex data analysis, generating optimized code, or exploring theoretical problems, but each possible use case requires rigorous testing to confirm effectiveness. The model’s open-source nature supports possible experimentation in these domains, yet careful validation remains essential.
- Advanced research
- Code development
- Mathematical problem-solving
- Extended text analysis
Quantized Versions & Hardware Requirements of Deepseek R1 32B
DeepSeek R1 32B in its q4 version requires a GPU with at least 24GB VRAM for deployment, as this quantized form balances precision and performance. Possible applications for this version may demand 24GB–40GB VRAM depending on workload, making it suitable for systems with mid-to-high-end GPUs. Users should verify their hardware compatibility to ensure smooth operation.
- fp16, q4, q8
Conclusion
DeepSeek R1 32B is a large-scale language model with 32 billion parameters and a 128k token context length, designed for advanced reasoning tasks using reinforcement learning without supervised fine-tuning. It is open-sourced, enabling research and deployment across diverse applications, though thorough evaluation is needed for specific use cases.
References
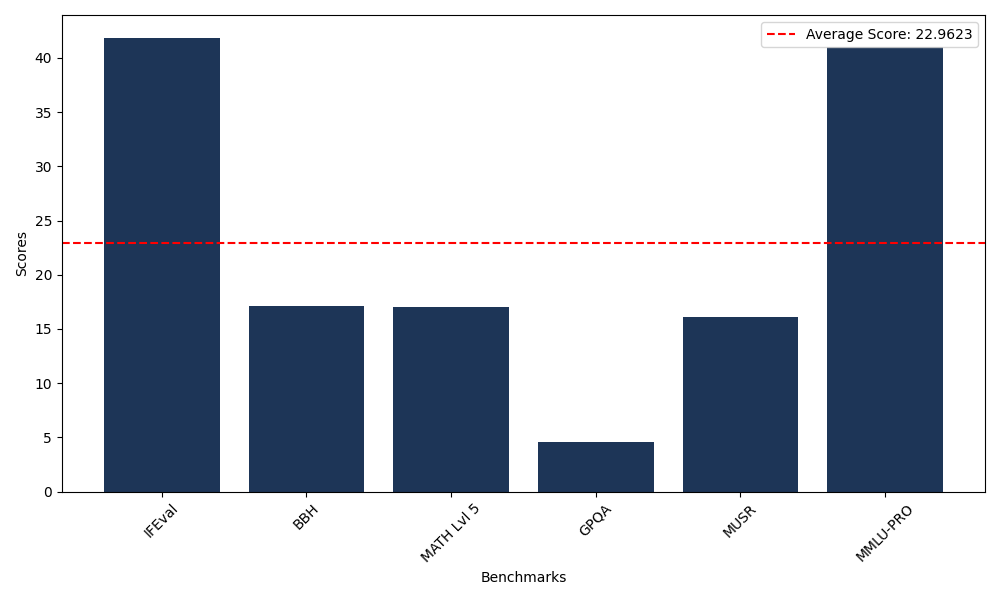
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 41.86 |
| Big Bench Hard (BBH) | 17.15 |
| Mathematical Reasoning Test (MATH Lvl 5) | 17.07 |
| General Purpose Question Answering (GPQA) | 4.59 |
| Multimodal Understanding and Reasoning (MUSR) | 16.14 |
| Massive Multitask Language Understanding (MMLU-PRO) | 40.96 |

Comments
No comments yet. Be the first to comment!
Leave a Comment