Deepseek R1 7B - Model Details

Deepseek R1 7B is a large language model developed by Deepseek, a company focused on advancing reasoning capabilities through reinforcement learning. With 7b parameters, it is designed to excel in complex tasks without relying on supervised fine-tuning. The model is released under the MIT License, ensuring open access and flexibility for research and development. Its architecture emphasizes scalable reasoning, making it a versatile tool for diverse applications.
Description of Deepseek R1 7B
DeepSeek-R1 is a large-scale reasoning model developed using reinforcement learning (RL) without supervised fine-tuning (SFT), emphasizing autonomous learning from scratch. It leverages cold-start data to enhance reasoning performance, achieving results comparable to OpenAI-o1 in math, code, and reasoning tasks. The model supports distillation into smaller variants, enabling efficient deployment across research, code generation, and mathematical problem-solving applications. Its design prioritizes scalability and adaptability, making it a versatile tool for complex reasoning challenges.
Parameters & Context Length of Deepseek R1 7B
DeepSeek R1 7B features 7b parameters, placing it in the small to mid-scale range of open-source LLMs, which ensures efficient performance for tasks requiring moderate computational resources. Its 128k context length falls into the very long context category, enabling the model to process extensive texts but demanding significant memory and processing power. This combination allows the model to balance resource efficiency with the ability to handle complex, lengthy inputs, making it suitable for applications like detailed document analysis or extended reasoning tasks.
- Parameter Size: 7b
- Context Length: 128k
Possible Intended Uses of Deepseek R1 7B
DeepSeek R1 7B is a model designed for research in large language models and reinforcement learning, with possible applications in code generation and debugging, mathematical problem-solving, and reasoning tasks. Its monolingual nature in Chinese and English suggests possible uses in specialized domains requiring language-specific processing, though these remain untested. The model’s focus on reasoning through reinforcement learning without supervised fine-tuning opens possible avenues for exploring autonomous learning systems, but further investigation is needed to confirm its effectiveness in these areas. Possible uses could extend to academic research, algorithm development, or task automation, though practical implementation would require thorough testing.
- research in large language models and reinforcement learning
- code generation and debugging
- mathematical problem-solving and reasoning tasks
Possible Applications of Deepseek R1 7B
DeepSeek R1 7B has possible applications in academic research, particularly for exploring reinforcement learning techniques and large language model development. Its possible use in code generation and debugging could support software development workflows, though this requires further validation. Potential applications in mathematical problem-solving and reasoning tasks might aid in educational or analytical contexts, but these need rigorous testing. Possible uses in tasks requiring extended context handling could benefit specific research domains, though practical implementation remains unproven. Each application must be thoroughly evaluated and tested before deployment to ensure reliability and suitability.
- research in large language models and reinforcement learning
- code generation and debugging
- mathematical problem-solving and reasoning tasks
- tasks requiring extended context handling
Quantized Versions & Hardware Requirements of Deepseek R1 7B
DeepSeek R1 7B with the q4 quantization requires a GPU with at least 16GB VRAM for efficient operation, making it suitable for systems with moderate hardware capabilities. This version balances precision and performance, allowing possible use on consumer-grade GPUs while maintaining reasonable inference speed. Other quantized versions include fp16 and q8, which may demand higher VRAM or computational resources.
- fp16, q4, q8
Conclusion
DeepSeek R1 7B is a large language model with 7b parameters, trained using reinforcement learning without supervised fine-tuning, and released under the MIT License. It features a 128k context length, enabling extended reasoning tasks while balancing performance and resource efficiency.
References
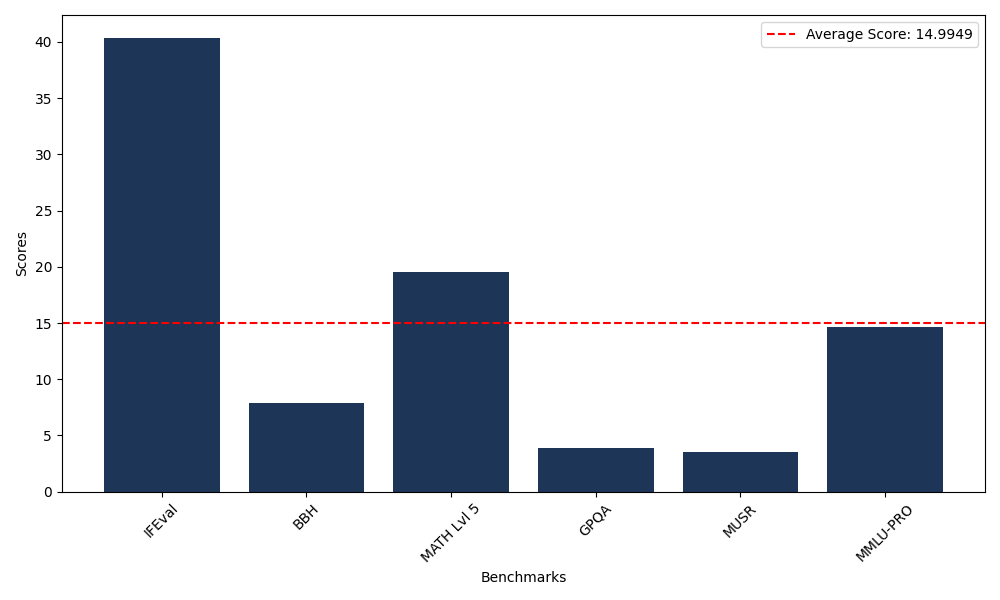
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 40.38 |
| Big Bench Hard (BBH) | 7.88 |
| Mathematical Reasoning Test (MATH Lvl 5) | 19.56 |
| General Purpose Question Answering (GPQA) | 3.91 |
| Multimodal Understanding and Reasoning (MUSR) | 3.55 |
| Massive Multitask Language Understanding (MMLU-PRO) | 14.68 |

Comments
No comments yet. Be the first to comment!
Leave a Comment