Deepseek R1 8B - Model Details

Deepseek R1 8B is a large language model developed by the Lm Studio Community, featuring 8 billion parameters. It operates under the MIT License, ensuring open accessibility and flexibility for users. The model's primary focus is on enhancing reasoning capabilities through reinforcement learning, avoiding supervised fine-tuning to achieve more autonomous and adaptable performance.
Description of Deepseek R1 8B
DeepSeek-R1 is a large-scale reasoning model developed using reinforcement learning (RL) without supervised fine-tuning (SFT). It incorporates cold-start data before RL to enhance reasoning performance, achieving results comparable to OpenAI-o1 across math, code, and reasoning tasks. The model supports distillation into smaller variants, enabling efficient deployment for research, code generation, and complex problem-solving. Its design emphasizes autonomous learning through RL, avoiding reliance on labeled datasets to improve adaptability and scalability.
Parameters & Context Length of Deepseek R1 8B
The DeepSeek R1 8B model features 8 billion parameters, placing it in the mid-scale category, offering balanced performance for moderate complexity tasks. Its 128k context length supports handling very long texts, though it requires significant computational resources. This combination makes it suitable for complex reasoning and extended input processing, but users should be prepared for higher resource demands.
- Parameter_Size: 8b
- Context_Length: 128k
Possible Intended Uses of Deepseek R1 8B
The DeepSeek R1 8B model presents possible applications in areas such as the research and development of reasoning models, where its reinforcement learning approach could offer potential insights into autonomous learning systems. It may also support possible uses in code generation and debugging, leveraging its reasoning capabilities to assist in writing or refining software. Additionally, the model’s design could enable potential tools for mathematical problem-solving and analysis, aiding in complex calculations or theoretical exploration. These possible uses require further investigation to determine their effectiveness and suitability for specific tasks.
- research and development of reasoning models
- code generation and debugging
- mathematical problem-solving and analysis
Possible Applications of Deepseek R1 8B
The DeepSeek R1 8B model offers possible applications in areas such as research and development of reasoning models, where its reinforcement learning approach could provide potential insights into autonomous learning systems. It may also support possible uses in code generation and debugging, leveraging its reasoning capabilities to assist in writing or refining software. Additionally, the model’s design could enable potential tools for mathematical problem-solving and analysis, aiding in complex calculations or theoretical exploration. These possible applications require further investigation to ensure their effectiveness and alignment with specific needs. Each application must be thoroughly evaluated and tested before use.
- research and development of reasoning models
- code generation and debugging
- mathematical problem-solving and analysis
Quantized Versions & Hardware Requirements of Deepseek R1 8B
The DeepSeek R1 8B model's medium q4 version requires a GPU with at least 16GB VRAM for efficient operation, along with 32GB of system memory and adequate cooling. This configuration supports balanced performance and precision for mid-scale tasks. The available quantized versions are fp16, q4, and q8.
Conclusion
The DeepSeek R1 8B is a large language model developed by the Lm Studio Community, featuring 8 billion parameters and operating under the MIT License, designed to enhance reasoning capabilities through reinforcement learning without supervised fine-tuning. With a 128k context length, it supports complex reasoning and problem-solving tasks, making it suitable for research, code generation, and mathematical analysis.
References
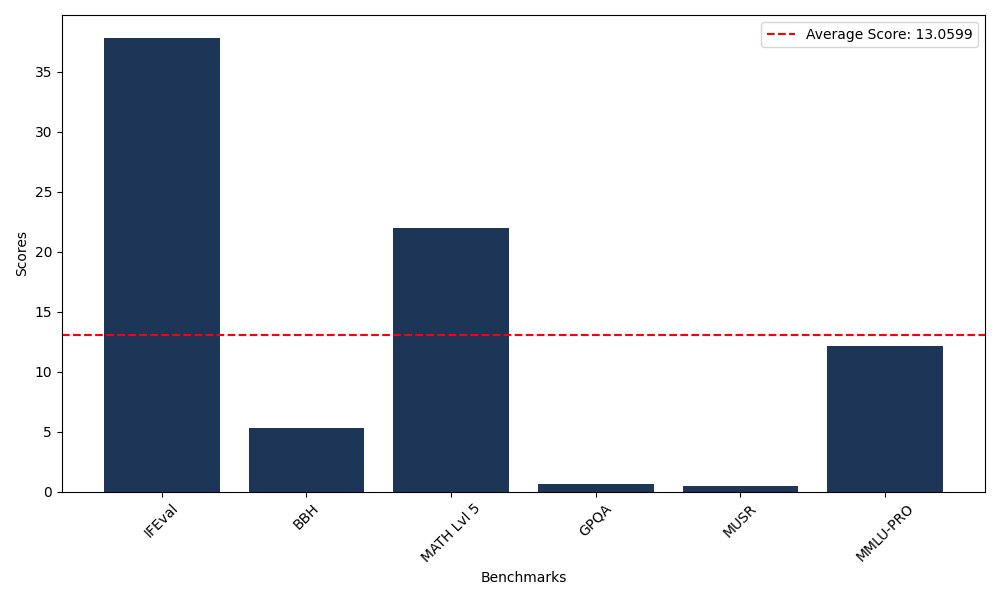
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 37.82 |
| Big Bench Hard (BBH) | 5.33 |
| Mathematical Reasoning Test (MATH Lvl 5) | 21.98 |
| General Purpose Question Answering (GPQA) | 0.67 |
| Multimodal Understanding and Reasoning (MUSR) | 0.46 |
| Massive Multitask Language Understanding (MMLU-PRO) | 12.10 |

Comments
No comments yet. Be the first to comment!
Leave a Comment