Glm4 9B - Model Details

Glm4 9B is a large language model developed by the Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University, featuring 9 billion parameters. It operates under the The Glm-4-9b License (GLM-4-9B) and is designed to excel in semantics, mathematics, reasoning, code, and knowledge evaluation across multiple languages. The model emphasizes robust performance and versatility in handling complex tasks.
Description of Glm4 9B
GLM-4-9B is the latest open-source version of the GLM-4 series by Zhipu AI, designed to outperform Llama-3-8B in tasks like multi-turn dialogue, web browsing, code execution, and long text reasoning with a 128K context length. It supports 26 languages, including Japanese, Korean, and German, and features a base context length of 8K. The model emphasizes versatility in handling complex reasoning, coding, and multilingual tasks while maintaining strong performance in semantic understanding and knowledge evaluation.
Parameters & Context Length of Glm4 9B
The Glm4 9B model features 9 billion parameters, placing it in the mid-scale category of open-source LLMs, offering a balance between performance and resource efficiency for moderate complexity tasks. Its 1024K context length falls into the very long context range, enabling advanced handling of extended texts but requiring significant computational resources. This combination allows the model to manage intricate reasoning and large-scale data while maintaining versatility across diverse applications.
- Name: Glm4 9B
- Parameter Size: 9b
- Context Length: 1024k
- Implications: Mid-scale parameters for balanced performance, very long context for extended text handling but high resource demands.
Possible Intended Uses of Glm4 9B
The Glm4 9B model presents possible applications in areas such as multi-turn dialogue, where it could support dynamic conversations, and web browsing, potentially aiding in information retrieval or analysis. Its code execution capabilities might enable possible use cases in scripting or automation, while custom tool calls could allow integration with external systems for specific tasks. The model’s long text reasoning might offer possible benefits for analyzing extensive documents or datasets. As a multilingual model, it supports German, Japanese, and Korean, opening possible opportunities for cross-lingual tasks. However, these possible uses require thorough investigation to ensure suitability for specific scenarios.
- multi-turn dialogue
- web browsing
- code execution
- custom tool calls
- long text reasoning
Possible Applications of Glm4 9B
The Glm4 9B model offers possible applications in areas such as multi-turn dialogue, where it could support possible use cases for interactive and context-aware conversations. Its code execution capabilities might enable possible benefits for automating tasks or generating scripts, while custom tool calls could allow possible integration with external systems for specific workflows. The model’s long text reasoning might also provide possible advantages for analyzing extensive documents or datasets. These possible applications require careful evaluation to ensure alignment with specific needs and constraints.
- multi-turn dialogue
- code execution
- custom tool calls
- long text reasoning
Quantized Versions & Hardware Requirements of Glm4 9B
The Glm4 9B model’s medium q4 version requires a GPU with at least 16GB VRAM for efficient operation, making it suitable for mid-range hardware while balancing precision and performance. This quantization reduces memory usage compared to full-precision models, allowing possible deployment on systems with moderate resources, though specific requirements may vary based on workload and additional constraints. Users should ensure their graphics card meets these thresholds and verify compatibility with the model’s architecture.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
The Glm4 9B is a large language model developed by the Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University, featuring 9 billion parameters and a 1024K context length. It is designed for tasks requiring advanced reasoning, multilingual support, and efficient performance across diverse applications.
References
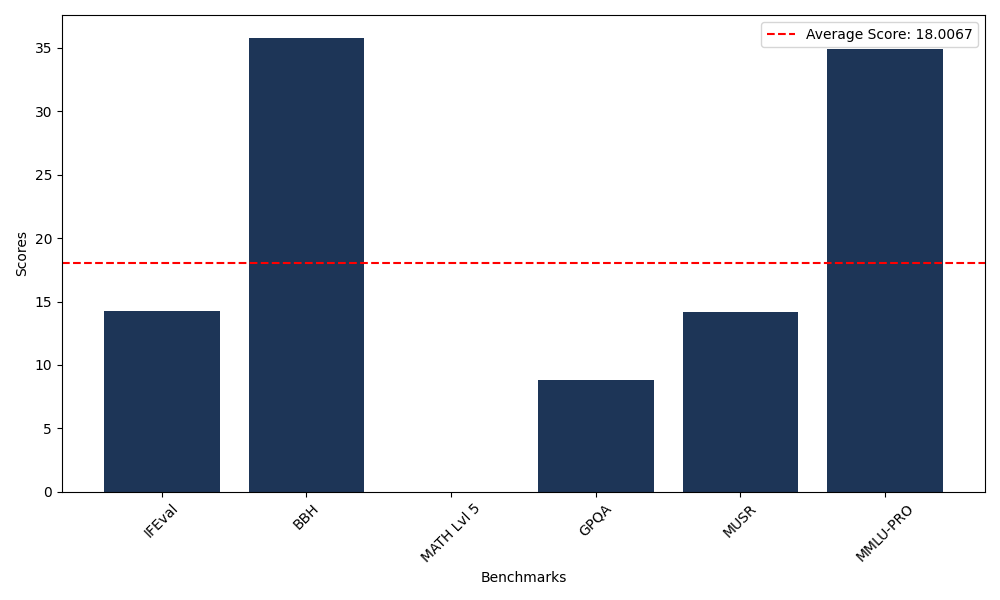
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 14.26 |
| Big Bench Hard (BBH) | 35.81 |
| Mathematical Reasoning Test (MATH Lvl 5) | 0.00 |
| General Purpose Question Answering (GPQA) | 8.84 |
| Multimodal Understanding and Reasoning (MUSR) | 14.19 |
| Massive Multitask Language Understanding (MMLU-PRO) | 34.94 |

Comments
No comments yet. Be the first to comment!
Leave a Comment