Mistral Openorca 7B - Model Details

Mistral Openorca 7B is a large language model developed by the community-driven project Openorca. It features 7 billion parameters, making it optimized for efficiency while maintaining strong performance on a variety of tasks. The model is specifically fine-tuned to excel in scenarios requiring up to 30 billion parameters, balancing capability with resource constraints. Its open and collaborative nature reflects the community-driven approach of its maintainer.
Description of Mistral Openorca 7B
Mistral Openorca 7B is a fine-tuned version of Mistral 7B using the OpenOrca dataset, which aims to reproduce the dataset from Microsoft Research's Orca Paper. It is optimized for consumer GPUs, achieves high performance on HuggingFace Leaderboard (106% of base model performance), and uses ChatML format for prompts. The model is suitable for tasks like question-answering, text generation, and research applications.
Parameters & Context Length of Mistral Openorca 7B
Mistral Openorca 7B is a large language model with 7 billion parameters and a context length of 8,000 tokens. The 7 billion parameters position it in the small to mid-scale range, offering fast and resource-efficient performance ideal for tasks requiring moderate complexity without excessive computational demands. Its 8,000-token context length enables handling of moderate-length texts, making it suitable for applications like detailed question-answering or extended dialogues while remaining constrained by the limitations of shorter contexts. These specifications reflect a balance between accessibility and capability, prioritizing efficiency for consumer-grade hardware.
- Parameter Size: 7b
- Context Length: 8k
Possible Intended Uses of Mistral Openorca 7B
Mistral Openorca 7B is a large language model designed for answering complex questions, generating human-like text, and assisting in research and development. Its capabilities suggest possible applications in areas such as drafting detailed explanations, creating creative content, or supporting exploratory analysis. However, these possible uses require thorough investigation to ensure alignment with specific goals and constraints. The model’s design emphasizes flexibility, but possible applications may vary depending on context, input quality, and evaluation criteria. Possible uses could involve tasks like summarizing technical documents, generating code snippets, or aiding in hypothesis testing, though these remain potential scenarios that need validation.
- answering complex questions
- generating human-like text
- assisting in research and development
Possible Applications of Mistral Openorca 7B
Mistral Openorca 7B is a large language model with possible applications in areas such as content creation, interactive dialogue systems, technical documentation drafting, and exploratory data analysis. Its possible use in generating human-like text could support creative writing or educational materials, while its possible role in dialogue systems might aid in developing conversational interfaces. The model’s possible utility for technical documentation could streamline the creation of detailed guides, and its possible application in data analysis might assist in summarizing or interpreting structured information. These possible scenarios highlight the model’s versatility, but each possible use requires thorough evaluation to ensure alignment with specific requirements and constraints.
- content creation
- interactive dialogue systems
- technical documentation drafting
- exploratory data analysis
Quantized Versions & Hardware Requirements of Mistral Openorca 7B
Mistral Openorca 7B’s medium q4 version is optimized for consumer GPUs with at least 16GB VRAM, balancing precision and performance for efficient deployment. This possible use requires a GPU with sufficient VRAM to handle the model’s 7 billion parameters, along with at least 32GB RAM and adequate cooling. While the q4 quantization reduces resource demands compared to higher-precision versions, possible applications may still vary based on system capabilities.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
Mistral Openorca 7B is a community-driven large language model with 7 billion parameters and an 8,000-token context length, optimized for efficiency and suitable for tasks requiring moderate complexity. It supports multiple quantized versions, including q4, and is designed to run on consumer GPUs with at least 16GB VRAM, balancing performance and resource usage.
References
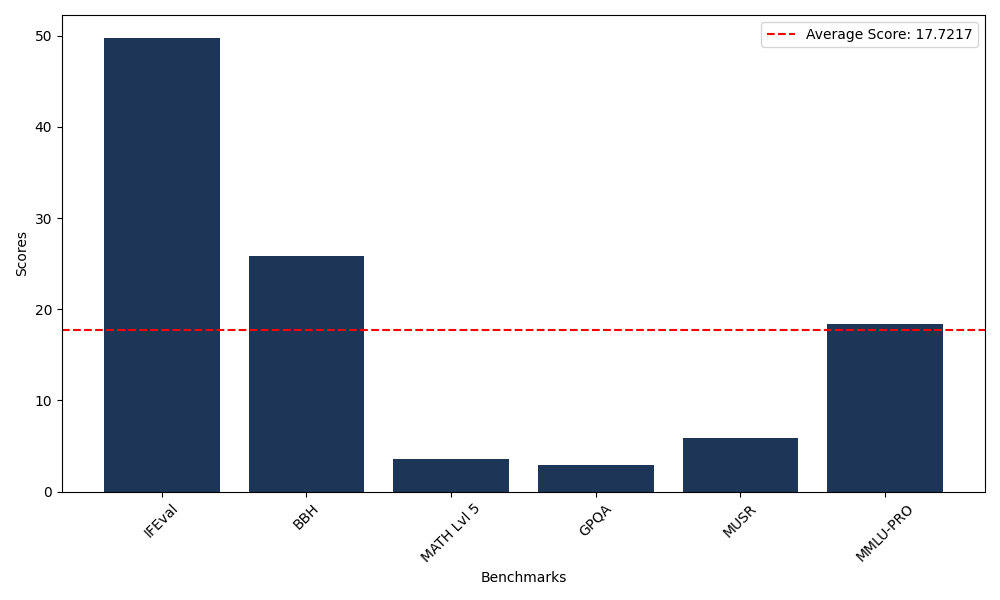
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 49.78 |
| Big Bench Hard (BBH) | 25.84 |
| Mathematical Reasoning Test (MATH Lvl 5) | 3.55 |
| General Purpose Question Answering (GPQA) | 2.91 |
| Multimodal Understanding and Reasoning (MUSR) | 5.89 |
| Massive Multitask Language Understanding (MMLU-PRO) | 18.37 |

Comments
No comments yet. Be the first to comment!
Leave a Comment