Mixtral 8X22B - Model Details

Mixtral 8X22B, developed by Mistral Ai, is a large language model with a parameter size of 8x22b, designed to efficiently balance computational resources through a sparse Mixture of Experts architecture. It is released under the Apache License 2.0.
Description of Mixtral 8X22B
Mixtral-8x22B is a pretrained generative Sparse Mixture of Experts model developed by Mistral Ai. It has a parameter size of 8x22b and operates as a base model, meaning it does not include built-in moderation mechanisms. The model is released under the Apache License 2.0, making it open-source and freely available for use and modification. Its architecture emphasizes efficiency by distributing computational load across specialized expert networks, enabling high performance with optimized resource utilization.
Parameters & Context Length of Mixtral 8X22B
The Mixtral-8x22B model features a parameter size of 8x22b, making it a large-scale language model capable of handling complex tasks with high computational power. Its context length of 64k tokens allows it to process and generate extended sequences, ideal for tasks requiring deep contextual understanding. The implications of this scale include enhanced performance for intricate applications but also demand significant computational resources and optimization for efficient deployment.
- Parameter Size: 8x22b
- Context Length: 64k
Possible Intended Uses of Mixtral 8X22B
The Mixtral-8x22B model offers possible applications in areas such as text generation, where it could assist with creative writing, content creation, or summarization tasks. Its possible use in code generation might support developers by suggesting snippets or automating repetitive coding patterns. Additionally, language translation could benefit from its capacity to handle complex linguistic structures across multiple languages. These possible uses require further exploration to ensure alignment with specific requirements and constraints. The model’s purpose as a versatile tool highlights its adaptability, but possible applications must be carefully evaluated before deployment.
- text generation
- code generation
- language translation
Possible Applications of Mixtral 8X22B
The Mixtral-8x22B model presents possible applications in domains such as text generation, where it could support content creation or creative writing tasks. Its possible use in code generation might aid developers by offering suggestions or automating repetitive coding workflows. Language translation could also benefit from its capacity to handle complex linguistic patterns across multiple languages. These possible applications require further investigation to ensure they align with specific needs and constraints. Each possible use case must be thoroughly evaluated and tested before deployment to confirm suitability and effectiveness.
- text generation
- code generation
- language translation
Quantized Versions & Hardware Requirements of Mixtral 8X22B
The Mixtral-8x22B model’s medium q4 version requires a GPU with at least 24GB VRAM for efficient operation, though multiple GPUs may be necessary due to its 176B parameters. This quantized version balances precision and performance, making it suitable for systems with at least 32GB RAM and adequate cooling. Additional considerations include a robust power supply and proper GPU thermal management.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
The Mixtral-8x22B is a large language model developed by Mistral Ai with 8x22b parameters, released under the Apache License 2.0. It leverages a sparse Mixture of Experts architecture to optimize computational efficiency while maintaining high performance for complex tasks.
References
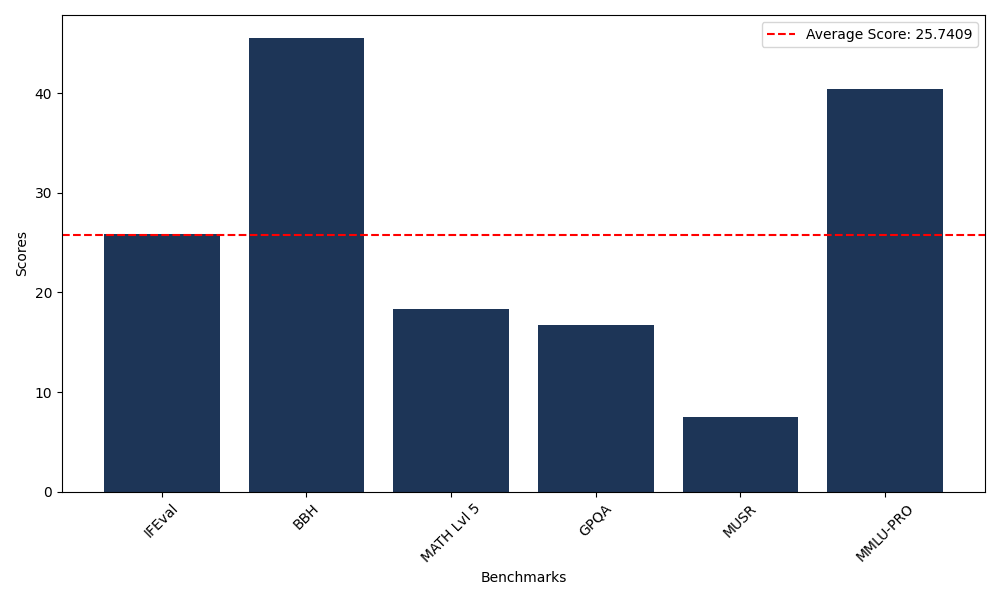
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 25.83 |
| Big Bench Hard (BBH) | 45.59 |
| Mathematical Reasoning Test (MATH Lvl 5) | 18.35 |
| General Purpose Question Answering (GPQA) | 16.78 |
| Multimodal Understanding and Reasoning (MUSR) | 7.46 |
| Massive Multitask Language Understanding (MMLU-PRO) | 40.44 |

Comments
No comments yet. Be the first to comment!
Leave a Comment