Mixtral 8X22B Instruct - Model Details

Mixtral 8X22B Instruct is a large language model developed by Mistral Ai, featuring a parameter size of 8x22b. It operates under the Apache License 2.0, making it an open-source solution. The model is designed to efficiently balance computational resources using a sparse Mixture of Experts architecture, optimizing performance while maintaining scalability.
Description of Mixtral 8X22B Instruct
The Mixtral-8x22B-Instruct-v0.1 is an instruct fine-tuned version of the Mixtral-8x22B-v0.1 large language model, specifically designed for interactive tasks. It leverages 22 billion parameters to deliver advanced language understanding and generation capabilities. This variant is optimized to handle complex queries and dynamic interactions, making it suitable for applications requiring real-time responsiveness and nuanced user engagement. Its foundation in the Mixture of Experts architecture ensures efficient resource utilization while maintaining high performance.
Parameters & Context Length of Mixtral 8X22B Instruct
The Mixtral 8X22B Instruct model features a parameter size of 8x22b (22 billion parameters), placing it in the large-scale category of open-source LLMs, which enables it to handle complex tasks with high accuracy but requires significant computational resources. Its context length of 4k tokens limits its ability to process very long texts, making it more suited for tasks requiring concise interactions rather than extended contextual analysis. This combination of parameters and context length suggests a balance between performance and efficiency, ideal for applications where resource constraints are a factor.
- Parameter Size: 8x22b (22 billion parameters) – powerful for complex tasks but resource-intensive.
- Context Length: 4k tokens – suitable for short to moderate tasks, limited for extended text processing.
Possible Intended Uses of Mixtral 8X22B Instruct
The Mixtral 8X22B Instruct model offers possible applications in areas such as text generation, code generation, and chatbot interactions, leveraging its large parameter size and specialized training. These possible uses could include creating dynamic content, assisting with programming tasks, or enabling conversational interfaces. However, the possible effectiveness of these applications depends on specific implementation details, contextual requirements, and further testing. The model’s design suggests it could support possible scenarios where high-quality language processing is needed, but possible limitations may arise based on the complexity of tasks or resource availability.
- Text generation
- Code generation
- Chatbot interactions
Possible Applications of Mixtral 8X22B Instruct
The Mixtral 8X22B Instruct model presents possible applications in domains such as text generation, code generation, and chatbot interactions, where its large parameter size and specialized training could enable possible benefits for tasks requiring nuanced language processing. Possible uses might include generating dynamic content, assisting with programming tasks, or enhancing conversational interfaces, though these possible scenarios would require careful assessment to ensure alignment with specific needs. Possible limitations could arise depending on the complexity of the task or the environment in which the model is deployed, highlighting the possible necessity of thorough testing before implementation.
- Text generation
- Code generation
- Chatbot interactions
Quantized Versions & Hardware Requirements of Mixtral 8X22B Instruct
The Mixtral 8X22B Instruct model’s medium q4 version requires a GPU with at least 16GB VRAM for efficient operation, as quantized models like q4 balance precision and performance while reducing memory demands. This possible configuration allows the model to run on mid-range hardware, though possible variations in implementation or workload may affect requirements. Users should verify their GPU’s specifications and available VRAM to ensure compatibility.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
The Mixtral 8X22B Instruct is a large language model with 8x22b parameters designed for interactive tasks, leveraging a sparse Mixture of Experts architecture to balance efficiency and performance. It operates under the Apache License 2.0, making it accessible for research and development, and is optimized for text generation, code generation, and chatbot interactions, though its deployment requires careful evaluation for specific use cases.
References
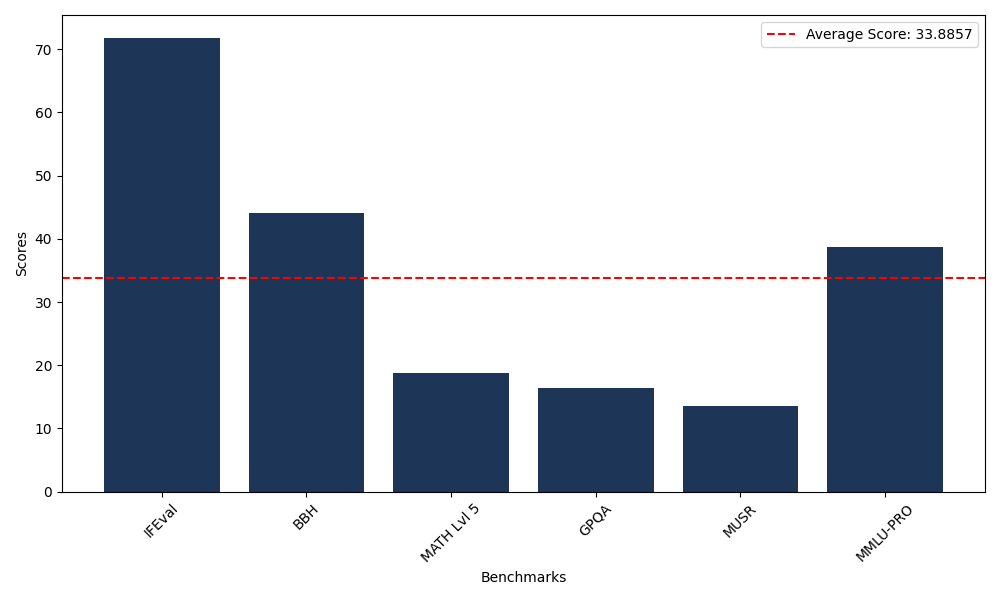
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 71.84 |
| Big Bench Hard (BBH) | 44.11 |
| Mathematical Reasoning Test (MATH Lvl 5) | 18.73 |
| General Purpose Question Answering (GPQA) | 16.44 |
| Multimodal Understanding and Reasoning (MUSR) | 13.49 |
| Massive Multitask Language Understanding (MMLU-PRO) | 38.70 |

Comments
No comments yet. Be the first to comment!
Leave a Comment