Mixtral 8X7B - Model Details

Mixtral 8X7B is a large language model developed by Mistral Ai with 8 billion parameters designed to efficiently balance computational resources using a sparse Mixture of Experts architecture. It is released under the Apache License 2.0, allowing flexible use and modification.
Description of Mixtral 8X7B
Mixtral-8x7B is a pretrained generative Sparse Mixture of Experts model that outperforms Llama 2 70B on most benchmarks tested. It functions as a base model without moderation mechanisms, making it suitable for customizable applications. The model is compatible with vLLM serving and Hugging Face transformers library, though it cannot be instantiated with Hugging Face yet. Its sparse architecture emphasizes efficiency, aligning with its focus on balancing computational resources.
Parameters & Context Length of Mixtral 8X7B
Mixtral-8x7B is a large language model with 8 billion parameters and a 4,000-token context length, designed to balance efficiency and performance. The 8 billion parameters place it in the mid-scale category, enabling it to handle moderate complexity while maintaining resource efficiency, whereas the 4,000-token context length limits its ability to process very long texts, making it better suited for tasks requiring shorter input-output sequences. These specifications reflect a focus on accessibility and practicality for a wide range of applications.
- Name: Mixtral-8x7B
- Parameter Size: 8 billion
- Context Length: 4,000 tokens
- Implications: Mid-scale performance for moderate tasks, limited long-context capabilities.
Possible Intended Uses of Mixtral 8X7B
Mixtral-8x7B is a versatile large language model that could be explored for research and development to test new algorithms or workflows, as its 8 billion parameters and 4,000-token context length provide a balance between efficiency and capability. It might also serve educational purposes by generating explanations or examples for learning, though its effectiveness in such roles would require further testing. General text generation could be another possible application, such as creating drafts or summaries, but its suitability for specific tasks would depend on additional evaluation. These uses are possible and may vary based on the context, requiring careful analysis before implementation.
- Intended Uses: research and development, educational purposes, general text generation
Possible Applications of Mixtral 8X7B
Mixtral-8x7B is a large language model that could be explored for research and development to test new algorithms or workflows, as its 8 billion parameters and 4,000-token context length provide a balance between efficiency and capability. It might also serve educational purposes by generating explanations or examples for learning, though its effectiveness in such roles would require further testing. General text generation could be another possible application, such as creating drafts or summaries, but its suitability for specific tasks would depend on additional evaluation. Creative writing or content ideation might also be a possible use case, though its performance in these areas would need careful analysis. These applications are possible and may vary based on the context, requiring thorough evaluation before implementation.
- Possible Applications: research and development, educational purposes, general text generation, creative writing or content ideation
Quantized Versions & Hardware Requirements of Mixtral 8X7B
Mixtral-8x7B in its medium q4 version requires a GPU with at least 16GB VRAM and system memory of at least 32GB to operate efficiently, making it suitable for devices with moderate to high-end graphics capabilities. The q4 quantization balances precision and performance, but users should verify their hardware meets these requirements to ensure smooth operation. Additional considerations include adequate GPU cooling and a power supply capable of supporting the GPU.
- Quantized Versions: fp16, q2, q3, q4, q5, q6, q8
Conclusion
Mixtral-8x7B is a large language model with 8 billion parameters and a 4,000-token context length, designed to efficiently balance computational resources through its sparse Mixture of Experts architecture. It is released under the Apache License 2.0, offering flexibility for various applications while maintaining performance and resource efficiency.
References
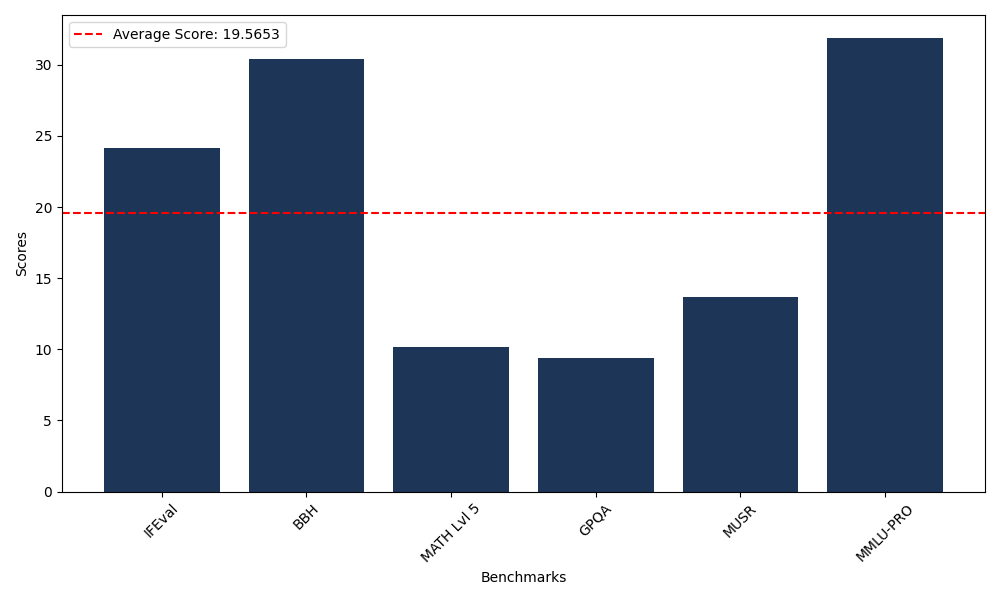
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 24.15 |
| Big Bench Hard (BBH) | 30.29 |
| Mathematical Reasoning Test (MATH Lvl 5) | 10.20 |
| General Purpose Question Answering (GPQA) | 8.50 |
| Multimodal Understanding and Reasoning (MUSR) | 12.58 |
| Massive Multitask Language Understanding (MMLU-PRO) | 31.66 |
| Instruction Following Evaluation (IFEval) | 23.26 |
| Big Bench Hard (BBH) | 30.40 |
| Mathematical Reasoning Test (MATH Lvl 5) | 9.37 |
| General Purpose Question Answering (GPQA) | 9.40 |
| Multimodal Understanding and Reasoning (MUSR) | 13.66 |
| Massive Multitask Language Understanding (MMLU-PRO) | 31.90 |

Comments
No comments yet. Be the first to comment!
Leave a Comment