Mixtral 8X7B Instruct - Model Details

Mixtral 8X7B Instruct is a large language model developed by Mistral Ai, featuring 8 billion parameters designed to efficiently balance computational resources with a sparse Mixture of Experts architecture. The model is released under the Apache License 2.0, making it accessible for both research and commercial use. Its architecture prioritizes performance while maintaining efficiency, offering a scalable solution for diverse natural language processing tasks.
Description of Mixtral 8X7B Instruct
Mixtral-8x7B is a pretrained generative Sparse Mixture of Experts model that demonstrates superior performance, outperforming Llama 2 70B on most benchmarks. It includes an Instruct version tailored for optimized outputs through a specific instruction format, enhancing its adaptability for task-oriented applications. The model leverages a sparse architecture to balance efficiency and capability, making it suitable for resource-conscious deployment while maintaining high-quality generative capabilities.
Parameters & Context Length of Mixtral 8X7B Instruct
Mixtral-8x7B has 8 billion parameters and a 4k token context length, placing it in the mid-scale category for parameter size, which offers a balance between performance and resource efficiency for moderate complexity tasks. Its 4k context length is suitable for short to moderate tasks but limits its ability to handle very long texts. The parameter size enables robust language understanding while maintaining efficiency, making it ideal for applications requiring speed and scalability. The context length ensures effective handling of concise inputs but may require additional techniques for extended content.
- Parameter Size: 8x7b (mid-scale, balanced performance)
- Context Length: 4k (short, suitable for brief tasks)
Possible Intended Uses of Mixtral 8X7B Instruct
Mixtral-8x7B is a versatile large language model designed for tasks requiring nuanced understanding and generation. Its 8x7b parameter size and 4k context length make it a possible tool for addressing complex queries with detailed explanations, as it can process and synthesize information from diverse sources. It could also serve as a possible aid for generating creative and coherent text content, offering flexibility in style and structure. Additionally, its architecture might support possible applications in coding tasks and problem-solving, where structured reasoning and code generation are needed. However, these possible uses require thorough testing and adaptation to specific scenarios, as their effectiveness may vary depending on implementation and context.
- answering complex questions with detailed explanations
- generating creative and coherent text content
- assisting with coding tasks and problem-solving
Possible Applications of Mixtral 8X7B Instruct
Mixtral-8x7B is a large language model with 8x7b parameters and a 4k context length, making it a possible candidate for tasks requiring nuanced understanding and generation. Its possible applications include answering complex questions with detailed explanations, as its architecture supports in-depth analysis and synthesis of information. It could also serve as a possible tool for generating creative and coherent text content, offering flexibility in adapting to different styles or formats. Additionally, it might be possible to use it for assisting with coding tasks and problem-solving, leveraging its structured reasoning capabilities. These possible uses are not guaranteed to be effective in all scenarios and require thorough evaluation to ensure alignment with specific needs. Each application must be thoroughly evaluated and tested before use.
- answering complex questions with detailed explanations
- generating creative and coherent text content
- assisting with coding tasks and problem-solving
Quantized Versions & Hardware Requirements of Mixtral 8X7B Instruct
Mixtral-8x7B with the q4 quantization requires a GPU with at least 16GB VRAM and 12GB–24GB VRAM for efficient operation, making it a possible choice for systems with moderate hardware capabilities. This version balances precision and performance, enabling deployment on devices with limited resources while maintaining reasonable computational efficiency. The fp16, q2, q3, q4, q5, q6, q8 quantized versions are available for different trade-offs between speed, accuracy, and resource usage.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
Mixtral-8x7B is a large language model with 8x7b parameters and a 4k context length, designed for efficient performance through a sparse Mixture of Experts architecture. It supports multiple quantized versions, including q4, to balance precision and resource requirements for diverse applications.
References
Benchmarks
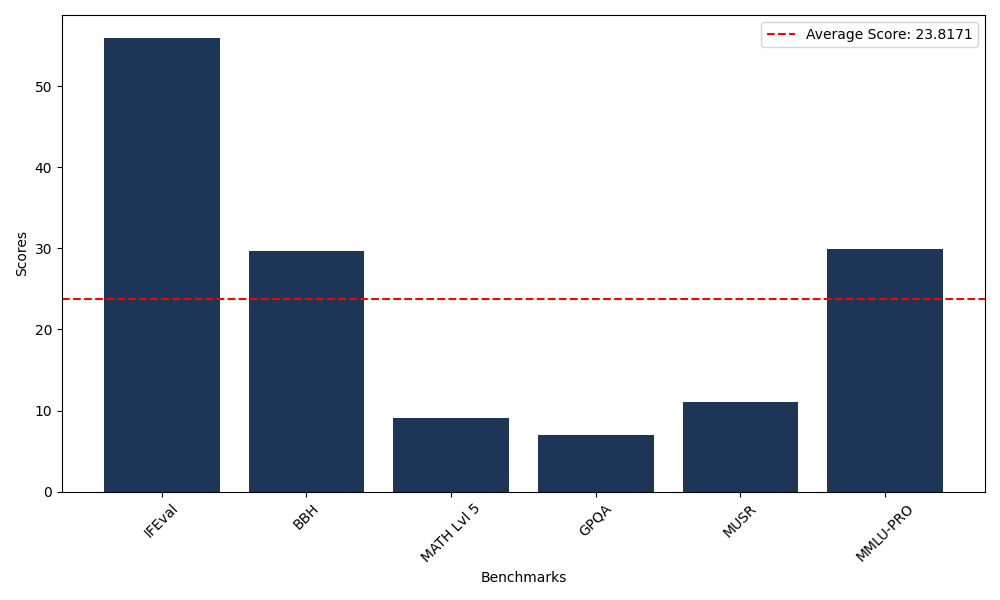
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 55.99 |
| Big Bench Hard (BBH) | 29.74 |
| Mathematical Reasoning Test (MATH Lvl 5) | 9.14 |
| General Purpose Question Answering (GPQA) | 7.05 |
| Multimodal Understanding and Reasoning (MUSR) | 11.07 |
| Massive Multitask Language Understanding (MMLU-PRO) | 29.91 |

Comments
No comments yet. Be the first to comment!
Leave a Comment