Nemotron Mini 4B Instruct - Model Details

Nemotron Mini 4B Instruct is a large language model developed by NVIDIA Enterprise with 4 billion parameters. It operates under the Nvidia Ai Foundation Models Community License Agreement (NAIFMCLA) and is designed for tasks like roleplay, retrieval augmented generation QA, and function calling. The model emphasizes practical applications through its specialized training and open licensing framework.
Description of Nemotron Mini 4B Instruct
Nemotron-Mini-4B-Instruct is a small language model (SLM) optimized through distillation, pruning, and quantization to enhance speed and enable on-device deployment. It is a fine-tuned version of nvidia/Minitron-4B-Base, which was itself pruned and distilled from the larger Nemotron-4 15B model using NVIDIA's LLM compression techniques. The model is specifically designed for roleplay, retrieval augmented generation QA (RAG QA), and function calling in English, with a context length of 4,096 tokens. Its compact size and efficiency make it suitable for applications requiring real-time interaction and resource-conscious execution.
Parameters & Context Length of Nemotron Mini 4B Instruct
Nemotron Mini 4B Instruct has 4 billion parameters, placing it in the small model category, which ensures fast inference and low resource consumption, making it ideal for simple tasks and on-device deployment. Its 4,096-token context length falls under short contexts, limiting its ability to process very long texts but aligning with its focus on roleplay, retrieval augmented generation QA, and function calling where concise interactions are key. The model’s design emphasizes efficiency and responsiveness for specific use cases.
- Parameter Size: 4b
- Context Length: 4k
Possible Intended Uses of Nemotron Mini 4B Instruct
Nemotron Mini 4B Instruct is a model designed for roleplaying, retrieval augmented generation (RAG) QA, and function calling, with possible uses in scenarios requiring interactive dialogue, question-answering with external data, or integrating with tools. Its small parameter size and moderate context length suggest it could be used for possible applications like creating conversational agents, enhancing chatbots with retrieval capabilities, or enabling task automation through function calls. However, these possible uses would need thorough testing to ensure they align with specific requirements, as the model’s design prioritizes efficiency over handling highly complex or resource-intensive tasks. The intended purposes highlight its suitability for environments where speed and simplicity are critical, but further exploration is necessary to confirm its effectiveness in real-world implementations.
- Possible uses: roleplaying, retrieval augmented generation (RAG) QA, function calling
Possible Applications of Nemotron Mini 4B Instruct
Nemotron Mini 4B Instruct is a model with possible applications in areas like roleplaying, retrieval augmented generation (RAG) QA, and function calling, which could be suitable for tasks requiring interactive dialogue, data-driven question-answering, or tool integration. Its possible uses might include creating conversational agents for entertainment, enhancing chatbots with retrieval capabilities, or enabling task automation through function calls. These possible applications could also extend to scenarios like content generation, customer support simulations, or educational tools, though their effectiveness would depend on specific implementation details. The model’s small parameter size and moderate context length suggest it is optimized for efficient, lightweight interactions, but possible uses in these domains would need thorough evaluation to ensure alignment with user needs. Each application must be thoroughly evaluated and tested before use.
- roleplaying
- retrieval augmented generation (RAG) QA
- function calling
Quantized Versions & Hardware Requirements of Nemotron Mini 4B Instruct
Nemotron Mini 4B Instruct with the medium Q4 quantization requires a GPU with at least 16GB VRAM and a system with 32GB RAM for efficient operation, making it suitable for devices with moderate hardware capabilities. This version balances precision and performance, allowing possible applications on consumer-grade GPUs like the RTX 3090 or similar. However, possible hardware requirements may vary based on workload and optimizations, so users should verify compatibility with their setup. Additional considerations include adequate cooling and a stable power supply.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
Nemotron Mini 4B Instruct is a compact language model with 4 billion parameters and a 4,096-token context length, optimized for roleplay, retrieval augmented generation QA, and function calling. It supports multiple quantized versions including fp16, q2, q3, q4, q5, q6, q8, making it adaptable for diverse hardware configurations while prioritizing efficiency and performance.
References
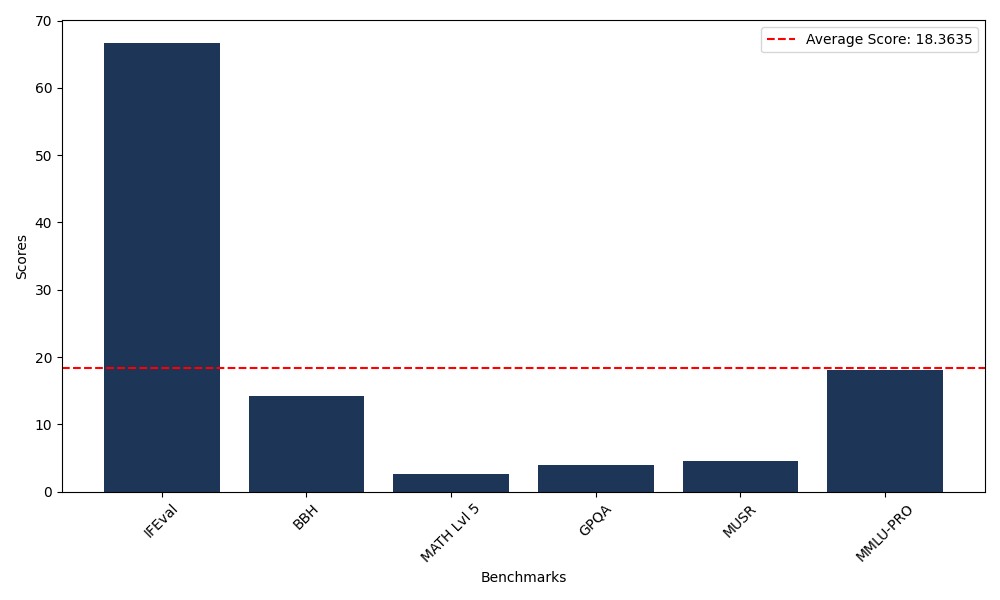
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 66.69 |
| Big Bench Hard (BBH) | 14.20 |
| Mathematical Reasoning Test (MATH Lvl 5) | 2.57 |
| General Purpose Question Answering (GPQA) | 4.03 |
| Multimodal Understanding and Reasoning (MUSR) | 4.62 |
| Massive Multitask Language Understanding (MMLU-PRO) | 18.07 |

Comments
No comments yet. Be the first to comment!
Leave a Comment