Openchat 7B - Model Details

Openchat 7B is a large language model developed by the Openchat community, featuring 7 billion parameters. It operates under the Apache License 2.0 (Apache-2.0), allowing flexible use and modification. The model is designed to enhance performance through C-RLFT, leveraging mixed-quality data without reliance on preference labels.
Description of Openchat 7B
OpenChat 3.5 1210 is an open-source language model with 7B parameters designed for coding, general tasks, and mathematical reasoning. It outperforms ChatGPT (March) and Grok-1 in benchmarks, offering two modes—coding/generalist and mathematical reasoning—alongside experimental evaluator capabilities. The model leverages mixed-quality data for training and supports deployment via an OpenAI-compatible API server.
Parameters & Context Length of Openchat 7B
OpenChat 3.5 1210 is a large language model with 7B parameters and a 8k context length, positioning it as a small to mid-scale model that balances efficiency and capability. The 7B parameter size ensures fast and resource-efficient performance, making it suitable for simple to moderately complex tasks, while the 8k context length allows it to handle moderate-length texts effectively, though it may struggle with extremely long documents. These specifications reflect a design prioritizing accessibility and practicality for a wide range of applications.
- Name: OpenChat 3.5 1210
- Parameter Size: 7B
- Context Length: 8k
- Implications: Small to mid-scale model for efficient, moderate-complexity tasks with moderate context handling.
Possible Intended Uses of Openchat 7B
OpenChat 3.5 1210 is a large language model with 7B parameters and a 8k context length, designed for code generation and debugging, general conversational tasks, and mathematical problem-solving. These are possible applications that could be explored further, as the model’s architecture and training data may support such uses. Possible uses might include assisting with coding challenges, engaging in everyday dialogue, or tackling mathematical queries, though these potential functions require rigorous testing to confirm their effectiveness. The model’s open-source nature and flexibility suggest possible opportunities for experimentation in these areas, but possible limitations could arise depending on specific implementation needs.
- code generation and debugging
- general conversational tasks
- mathematical problem-solving
Possible Applications of Openchat 7B
OpenChat 3.5 1210 is a large language model with 7B parameters and a 8k context length, which could support possible applications such as code generation and debugging, general conversational tasks, mathematical problem-solving, and content creation. These possible uses might include assisting with coding challenges, engaging in everyday dialogue, tackling mathematical queries, or generating text for creative or educational purposes. However, these potential functions require thorough evaluation to ensure they align with specific needs, as the model’s performance in these areas remains possible but unverified. Each possible application must be rigorously tested before deployment to confirm its effectiveness and suitability.
- code generation and debugging
- general conversational tasks
- mathematical problem-solving
- content creation
Quantized Versions & Hardware Requirements of Openchat 7B
OpenChat 3.5 1210’s medium q4 version requires a GPU with at least 16GB VRAM and 12GB–24GB VRAM for optimal performance, making it suitable for systems with mid-range graphics cards. This quantized version balances precision and efficiency, but users should verify their GPU’s specifications to ensure compatibility. Possible applications of this model may vary, and hardware suitability should be confirmed before deployment.
fp16, q2, q3, q4, q5, q6, q8
Conclusion
OpenChat 3.5 1210 is a large language model with 7B parameters and a 8k context length, designed for code generation and debugging, general conversational tasks, and mathematical problem-solving. These possible applications require thorough evaluation to ensure suitability for specific use cases.
References
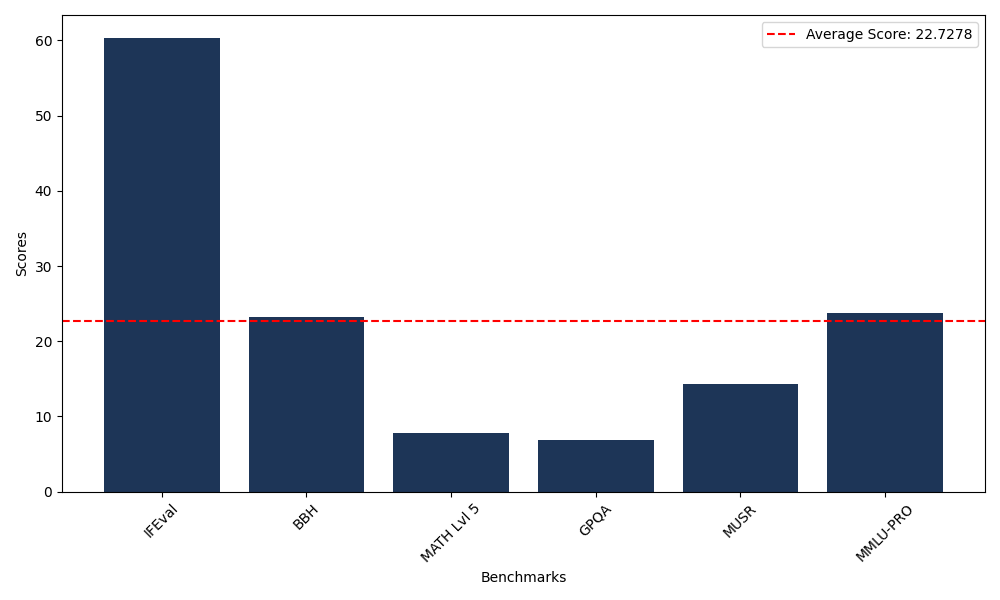
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 60.37 |
| Big Bench Hard (BBH) | 23.24 |
| Mathematical Reasoning Test (MATH Lvl 5) | 7.85 |
| General Purpose Question Answering (GPQA) | 6.82 |
| Multimodal Understanding and Reasoning (MUSR) | 14.28 |
| Massive Multitask Language Understanding (MMLU-PRO) | 23.80 |

Comments
No comments yet. Be the first to comment!
Leave a Comment