Openhermes 7B - Model Details

Openhermes 7B is a large language model developed by Teknium, a company, featuring 7 billion parameters. It is fine-tuned on diverse, openly available datasets to enhance its performance across various tasks.
Description of Openhermes 7B
OpenHermes 7B is a 7 billion parameter large language model developed by Teknium. It is the first fine-tune of the Hermes dataset using a fully open-source dataset, leveraging sample packing to optimize training efficiency by improving dataset token averages. The model was trained on 242,000 entries of primarily GPT-4 generated data from open datasets such as GPTeacher, WizardLM, Airoboros, Camel-AI, and CodeAlpaca, while excluding OpenAI refusals, disclaimers, and 'As an AI' examples. Its training data mix resembles Nous-Hermes but avoids private datasets like Nous-Instruct and PDACTL. The WANDB project is publicly accessible, ensuring transparency in the training process.
Parameters & Context Length of Openhermes 7B
Openhermes 7B is a 7 billion parameter model with a 4,000 token context length, making it well-suited for tasks requiring efficiency and moderate complexity. The 7B parameter size places it in the small-to-mid-scale category, offering fast inference and lower resource demands, ideal for applications where simplicity and speed are prioritized. Its 4,000 token context length falls into the short-context range, enabling effective handling of concise inputs but limiting its ability to process extended texts without additional optimizations. This balance makes it accessible for a wide range of use cases while maintaining performance within its constraints.
- Parameter Size: 7b (small-to-mid-scale, efficient for simple tasks)
- Context Length: 4k (short context, suitable for brief interactions)
Possible Intended Uses of Openhermes 7B
Openhermes 7B is a 7 billion parameter model designed for code generation, question answering, and text summarization, with possible applications in areas like software development, educational tools, and content creation. Its open-source nature and 4,000 token context length make it a possible tool for tasks requiring concise, accurate responses or structured output. However, these possible uses would need thorough testing to ensure alignment with specific requirements, as the model’s performance may vary depending on the complexity of the task. Possible scenarios could include assisting developers with coding challenges, providing summaries for research materials, or answering technical questions. While the model’s design supports these possible functions, further exploration is necessary to confirm their effectiveness in real-world settings.
- Intended Uses: code generation, question answering, text summarization
Possible Applications of Openhermes 7B
Openhermes 7B is a 7 billion parameter model with 4,000 token context length, offering possible applications in areas like code generation, question answering, and text summarization. Its possible use cases could include assisting developers with coding tasks, providing concise answers to technical queries, or condensing lengthy documents into summaries. Possible scenarios might involve educational tools for explaining concepts, collaborative writing support, or automating repetitive text-based workflows. While these possible functions align with the model’s design, they remain possible opportunities that require thorough testing to ensure reliability and suitability for specific tasks. Each possible application must be carefully evaluated and validated before deployment to confirm its effectiveness and alignment with user needs.
- Possible Applications: code generation, question answering, text summarization
Quantized Versions & Hardware Requirements of Openhermes 7B
Openhermes 7B's medium q4 version requires a GPU with at least 16GB VRAM and 32GB system RAM for smooth operation, making it suitable for mid-range hardware. This quantized version balances precision and performance, allowing possible use on consumer-grade GPUs like the RTX 3090 or similar. However, possible variations in performance may depend on specific configurations and workload demands.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
Openhermes 7B is a 7 billion parameter open-source large language model developed by Teknium, trained on diverse, publicly available datasets with a 4,000 token context length, making it suitable for tasks requiring efficiency and moderate complexity. Its open-source nature and sample packing optimization enhance training efficiency, while its moderate parameter size and context length position it as a versatile tool for applications like code generation, question answering, and text summarization.
References
Benchmarks
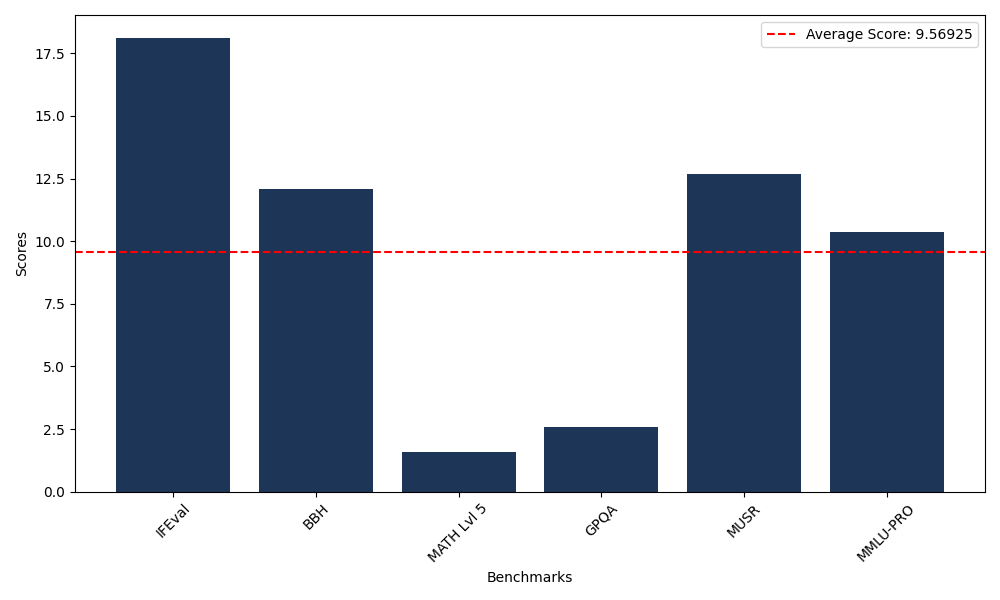
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 18.13 |
| Big Bench Hard (BBH) | 12.08 |
| Mathematical Reasoning Test (MATH Lvl 5) | 1.59 |
| General Purpose Question Answering (GPQA) | 2.57 |
| Multimodal Understanding and Reasoning (MUSR) | 12.68 |
| Massive Multitask Language Understanding (MMLU-PRO) | 10.37 |

Comments
No comments yet. Be the first to comment!
Leave a Comment