Orca Mini 7B - Model Details

The Orca Mini 7B is a large language model developed by the Psmathur-Orca community. It features a parameter size of 7b, making it suitable for a wide range of applications. The model is released under the Creative Commons Attribution Non Commercial Share Alike 4.0 International (CC-BY-NC-SA-4.0) license, ensuring it can be used and modified with proper attribution while restricting commercial exploitation. Designed with advanced architectures, it is optimized for diverse tasks requiring flexibility and efficiency.
Description of Orca Mini 7B
The Orca Mini 7B is an OpenLLaMa-7B model trained on explain-tuned datasets derived from WizardLM, Alpaca, and Dolly-V2. It employs techniques from the Orca Research Paper to generate custom datasets, enabling the model to learn thought processes from a teacher model (ChatGPT). Optimized for instruction-following tasks, it leverages 8x A100(80G) GPUs and DeepSpeed with ZeRO stage 3 for training. The model has a max length of 1024 during training, ensuring efficient handling of complex instructions. Its architecture emphasizes flexibility and adaptability for diverse applications requiring precise and context-aware responses.
Parameters & Context Length of Orca Mini 7B
The Orca Mini 7B model has 7b parameters, placing it in the small to mid-scale range of open-source LLMs, which ensures resource efficiency and fast inference for tasks requiring moderate complexity. Its 1k context length, equivalent to 1024 tokens, allows it to handle short to moderate-length inputs effectively but limits its ability to process very long texts. This combination makes it well-suited for instruction-following tasks and applications where speed and simplicity are prioritized over handling extensive context.
- Parameter Size: 7b
- Context Length: 1k
Possible Intended Uses of Orca Mini 7B
The Orca Mini 7B model has possible applications in areas such as text generation, where it could create content for creative or informational purposes, and code generation, potentially assisting with writing or debugging scripts. It might also serve as a tool for question answering, providing responses to queries based on its training data. These possible uses highlight its flexibility but require further exploration to ensure effectiveness and alignment with specific needs. The model’s design suggests it could support tasks where adaptability and efficiency are key, though its performance in real-world scenarios would depend on careful testing and refinement.
- text generation
- code generation
- question answering
Possible Applications of Orca Mini 7B
The Orca Mini 7B model has possible applications in areas such as text generation, where it could create content for creative or informational purposes, and code generation, potentially assisting with writing or debugging scripts. It might also serve as a tool for question answering, providing responses to queries based on its training data. Possible uses could extend to tasks like summarization or dialogue modeling, though these would require further exploration. These potential applications highlight its flexibility but necessitate thorough evaluation to ensure suitability for specific tasks. Each possible use case must be carefully assessed and tested before deployment to confirm alignment with intended goals.
- text generation
- code generation
- question answering
Quantized Versions & Hardware Requirements of Orca Mini 7B
The Orca Mini 7B model's medium q4 version requires a GPU with at least 16GB VRAM and 32GB system memory for efficient operation. These requirements ensure a balance between precision and performance, making it suitable for systems with moderate hardware capabilities. Users should verify their graphics card and system specifications to confirm compatibility.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
The Orca Mini 7B is a 7b parameter model developed by the Psmathur-Orca community, released under the Creative Commons Attribution Non Commercial Share Alike 4.0 International (CC-BY-NC-SA-4.0) license, and optimized for instruction-following tasks with a 1k context length. It balances efficiency and adaptability for diverse applications while requiring careful evaluation for specific use cases.
References
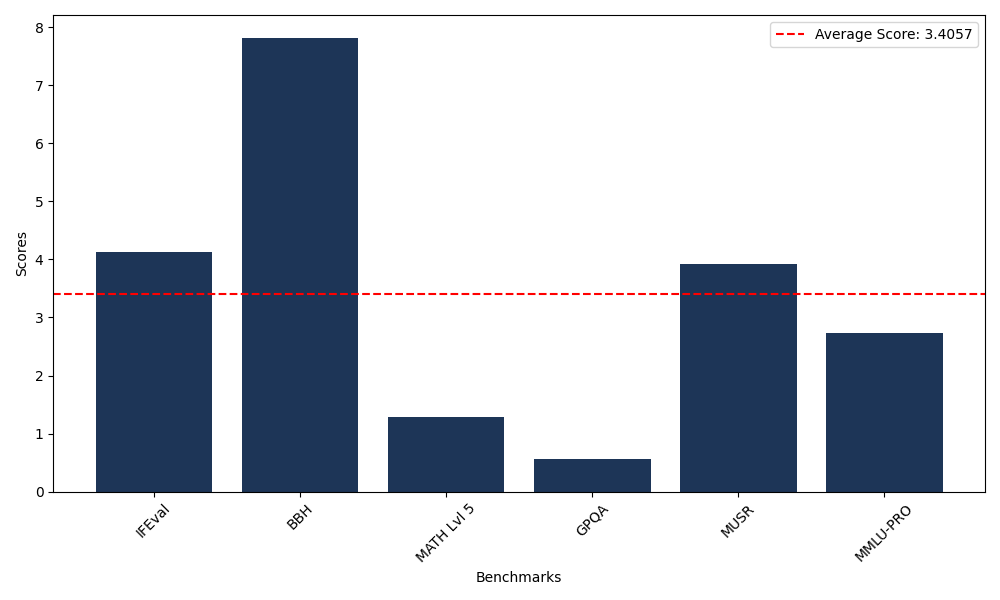
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 4.12 |
| Big Bench Hard (BBH) | 7.82 |
| Mathematical Reasoning Test (MATH Lvl 5) | 1.28 |
| General Purpose Question Answering (GPQA) | 0.56 |
| Multimodal Understanding and Reasoning (MUSR) | 3.92 |
| Massive Multitask Language Understanding (MMLU-PRO) | 2.73 |

Comments
No comments yet. Be the first to comment!
Leave a Comment