Orca2 13B - Model Details

Orca2 13B is a large language model developed by Microsoft with 13 billion parameters, designed to enhance reasoning abilities through synthetic data fine-tuning. It operates under the Microsoft Research License Terms (MSRLT), allowing for flexible use while adhering to specific research and development guidelines. The model emphasizes improved logical and analytical capabilities, making it suitable for complex tasks requiring deeper understanding and inference.
Description of Orca2 13B
Orca 2 is a research-focused large language model fine-tuned from LLaMA-2, designed to enhance reasoning capabilities through synthetic data. It excels in tasks like reasoning over user data, reading comprehension, math problem solving, and text summarization. The model is not optimized for chat interactions and requires fine-tuning for specific tasks. It inherits limitations from its LLaMA-2 base, including data biases, contextual understanding gaps, and potential hallucinations.
Parameters & Context Length of Orca2 13B
Orca2 13B is a mid-scale large language model with 13b parameters, offering a balance between performance and resource efficiency for moderate complexity tasks. Its 4k context length supports short to moderate-length inputs but limits its ability to process very long texts effectively. The parameter size enables robust reasoning and task handling while remaining more accessible than larger models, though it may lack the depth of 70B+ systems. The context length restricts its suitability for extended narratives or extensive data analysis without additional optimization.
- Parameter Size: 13b (mid-scale, balanced performance for moderate complexity)
- Context Length: 4k (short context, suitable for brief tasks but limited for long texts)
Possible Intended Uses of Orca2 13B
Orca2 13B is a large language model designed for research on small language models (SLMs) capabilities, assessment of reasoning abilities in synthetic data training, and development of better frontier models through experimental workflows. Its 13b parameter size and focus on synthetic data fine-tuning make it a possible tool for exploring how reasoning skills can be enhanced without relying on traditional datasets. Possible applications include testing the effectiveness of synthetic data in improving logical inference, analyzing the scalability of smaller models for specific tasks, and experimenting with new training methodologies. However, these possible uses require thorough investigation to determine their viability and limitations. The model’s design emphasizes flexibility for research, but its 4k context length and mid-scale parameters mean it may not be suitable for all scenarios.
- research on small language models (slms) capabilities
- assessment of reasoning abilities in synthetic data training
- development of better frontier models through experimental workflows
Possible Applications of Orca2 13B
Orca2 13B is a large language model with 13b parameters and a 4k context length, making it a possible tool for exploring advanced reasoning tasks through synthetic data. Possible applications include testing how synthetic data improves logical inference in smaller models, experimenting with training methodologies to enhance reasoning, and analyzing the scalability of mid-scale models for specific research goals. Possible uses might also extend to developing frameworks for evaluating model performance in controlled environments or refining experimental workflows for frontier model development. However, these possible applications require thorough evaluation to ensure alignment with specific objectives and constraints. Each application must be thoroughly evaluated and tested before use.
- research on small language models (slms) capabilities
- assessment of reasoning abilities in synthetic data training
- development of better frontier models through experimental workflows
Quantized Versions & Hardware Requirements of Orca2 13B
Orca2 13B’s medium q4 version is optimized for a balance between precision and performance, requiring a GPU with 12GB - 24GB VRAM for efficient operation. This makes it suitable for systems with mid-range graphics cards, though additional system memory (at least 32GB RAM) and adequate cooling are recommended. The model’s quantized nature reduces resource demands compared to full-precision versions, but deployment still depends on specific hardware capabilities.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
Orca2 13B is a large language model with 13b parameters and a 4k context length, optimized for research on small language models (SLMs) and synthetic data training to enhance reasoning abilities. It is designed for experimental workflows and task-specific fine-tuning, with potential applications in controlled environments requiring analytical capabilities.
References
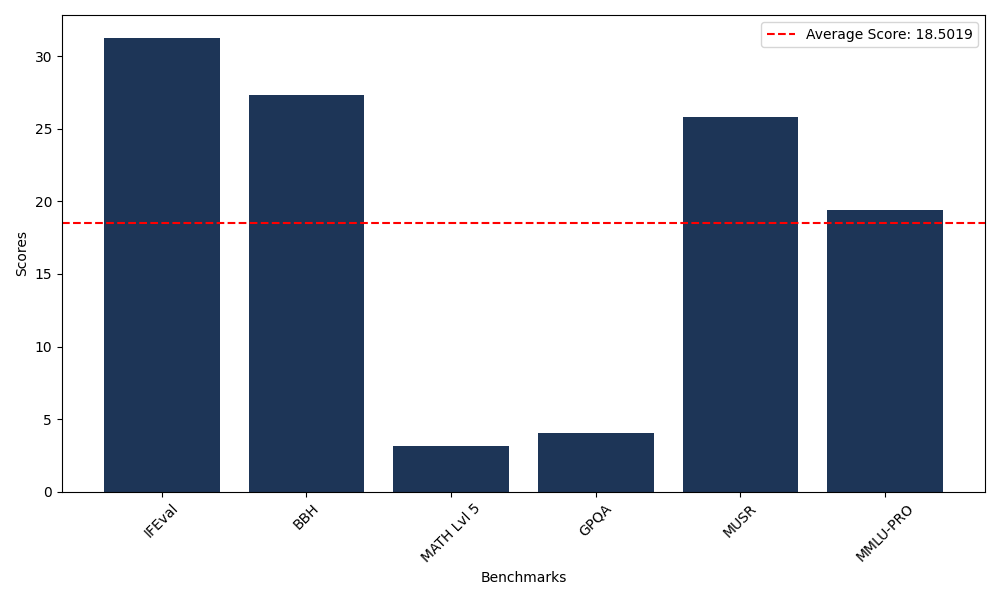
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 31.28 |
| Big Bench Hard (BBH) | 27.31 |
| Mathematical Reasoning Test (MATH Lvl 5) | 3.17 |
| General Purpose Question Answering (GPQA) | 4.03 |
| Multimodal Understanding and Reasoning (MUSR) | 25.79 |
| Massive Multitask Language Understanding (MMLU-PRO) | 19.44 |

Comments
No comments yet. Be the first to comment!
Leave a Comment