Qwen 0.5B

Qwen 0.5B is a large language model developed by Qwen, a company, featuring 0.5 billion parameters. It is released under the Tongyi Qianwen Research License Agreement (TQRLA), Tongyi Qianwen License Agreement (TQ-LA), Tongyi Qianwen Research License Agreement (TQRLA), Tongyi Qianwen Research License Agreement (TQRLA), and Tongyi Qianwen Research License Agreement (TQRLA). The model focuses on enhancing human preference in chat interactions.
Description of Qwen 0.5B
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on a vast dataset. It introduces 8 model sizes, including 0.5B, 1.8B, 4B, 7B, 14B, 32B, 72B dense models, and an MoE model of 14B with 2.7B activated. Key improvements over previous versions include significant performance enhancements in chat models, multilingual support for both base and chat models, and stable 32K context length across all sizes. The model emphasizes enhanced human preference in chat interactions and broader language capabilities.
Parameters & Context Length of Qwen 0.5B
Qwen 0.5B is a large language model with 0.5b parameters and a 32k context length. The 0.5b parameter size places it in the small model category, offering fast and resource-efficient performance suitable for simple tasks. The 32k context length falls into the long context range, enabling effective handling of extended texts but requiring more computational resources. These features make it ideal for applications where efficiency and extended context are needed without the overhead of larger models.
- Parameter Size: 0.5b
- Context Length: 32k
Possible Intended Uses of Qwen 0.5B
Qwen 0.5B is a large language model with 0.5b parameters and a 32k context length, designed for a range of possible applications. Its text generation capabilities could support tasks like drafting content, creating summaries, or generating creative writing, though further testing would be needed to confirm effectiveness. The multilingual communication feature suggests it might assist in translating or interpreting between languages, but this would require validation across diverse linguistic contexts. The code generation potential could enable assistance with writing or debugging code, though its accuracy and reliability in technical scenarios would need thorough evaluation. These possible uses highlight the model’s flexibility but also underscore the importance of careful exploration before deployment.
- text generation
- multilingual communication
- code generation
Possible Applications of Qwen 0.5B
Qwen 0.5B is a large language model with 0.5b parameters and a 32k context length, which could have possible applications in text generation, multilingual communication, and code generation. These possible uses might include creating content, facilitating cross-language interactions, or assisting with coding tasks. However, each possible application would require thorough evaluation to ensure suitability and effectiveness. The model's design suggests it could support these areas, but further testing is essential before deployment. Each application must be thoroughly evaluated and tested before use.
- text generation
- multilingual communication
- code generation
Quantized Versions & Hardware Requirements of Qwen 0.5B
Qwen 0.5B is a large language model with a medium Q4 quantized version, which balances precision and performance. This version likely requires a GPU with at least 8GB VRAM and 32GB system memory for smooth operation, though exact needs depend on the specific workload. The Q4 quantization reduces resource demands compared to higher-precision formats, making it suitable for devices with moderate hardware. However, these possible requirements should be verified against the user’s system specifications.
- fp16, q2, q3, q32, q4, q5, q6, q8
Conclusion
Qwen 0.5B is a large language model with 0.5b parameters and a 32k context length, designed for efficient performance across various tasks. It supports multiple quantized versions, including Q4, to optimize resource usage while maintaining effectiveness.
References
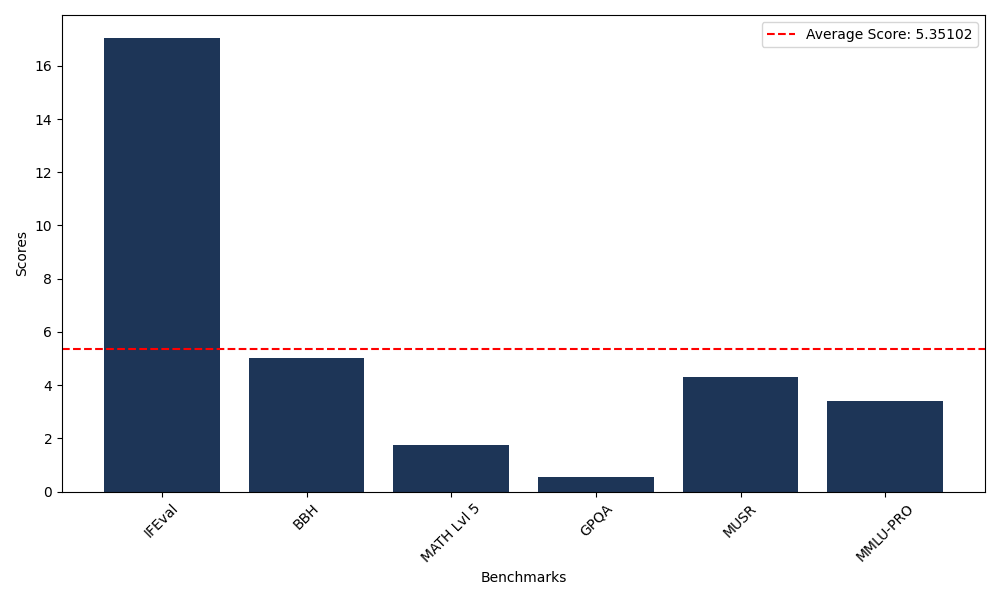
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 17.06 |
| Big Bench Hard (BBH) | 5.04 |
| Mathematical Reasoning Test (MATH Lvl 5) | 1.74 |
| General Purpose Question Answering (GPQA) | 0.56 |
| Multimodal Understanding and Reasoning (MUSR) | 4.30 |
| Massive Multitask Language Understanding (MMLU-PRO) | 3.41 |