Qwen 110B - Model Details

Qwen 110B is a large language model developed by Qwen, a company, featuring 110b parameters. It operates under the Tongyi Qianwen Research License Agreement (TQRLA), Tongyi Qianwen License Agreement (TQ-LA), and Tongyi Qianwen License Agreement (TQ-LA). The model emphasizes improved human preference in chat models, aiming to enhance interactions through advanced natural language processing capabilities.
Description of Qwen 110B
Qwen1.5 is the beta version of Qwen2, a transformer-based decoder-only language model pretrained on extensive data. It includes 9 model sizes ranging from 0.5B to 110B parameters, featuring dense models and an MoE model with 14B parameters and 2.7B activated. The model demonstrates significant performance improvements in chat models, multilingual support, and a stable 32K context length. It employs Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, and an improved tokenizer adapted for multiple natural languages and codes.
Parameters & Context Length of Qwen 110B
Qwen 110B is a large language model with 110b parameters, placing it in the category of very large models that excel at complex tasks but require significant computational resources. Its 32k context length allows for handling extended texts, making it suitable for long-form content while demanding more processing power.
- Name: Qwen 110B
- Parameter_Size: 110b (Very Large Models, 70B+; Best for complex tasks, but resource-intensive)
- Context_Length: 32k (Long Contexts, 8K-128K; Ideal for long texts, requires more resources)
Possible Intended Uses of Qwen 110B
Qwen 110B is a large language model with 110b parameters that could enable possible applications in areas like text generation, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). These possible uses might include creating highly customized language models for specific tasks, improving model alignment with user preferences through iterative training, or exploring new methods for optimizing performance in dynamic environments. However, these possible applications require thorough investigation to ensure they meet technical, ethical, and practical requirements. The model’s scale and flexibility suggest it could support possible advancements in natural language processing, but further research is needed to validate its effectiveness in real-world scenarios.
- text generation
- supervised fine-tuning (sft)
- reinforcement learning from human feedback (rlhf)
Possible Applications of Qwen 110B
Qwen 110B is a large-scale language model with 110b parameters and a 32k context length, which could enable possible applications in areas like generating complex textual content, refining model behavior through iterative training, or exploring advanced natural language processing tasks. These possible uses might include creating highly detailed narratives, optimizing models for specific user interactions, or handling extended conversations with nuanced context. However, these possible applications require careful evaluation to ensure they align with technical and ethical standards. The model’s scale and flexibility suggest it could support possible advancements in fields like education, research, or creative workflows, but each possible use case must be thoroughly tested before deployment.
- text generation
- supervised fine-tuning (sft)
- reinforcement learning from human feedback (rlhf)
- complex data analysis tasks
Quantized Versions & Hardware Requirements of Qwen 110B
The medium q4 version of the large language model requires a GPU with at least 16GB VRAM for optimal performance, making it suitable for mid-sized models. Users should ensure their graphics card meets this requirement, along with at least 32GB system memory, to handle the model’s computational demands. This version balances precision and efficiency, allowing for possible deployment on standard consumer-grade GPUs, though specific configurations may vary.
- fp16, q2, q3, q32, q4, q5, q6, q8
Conclusion
Qwen 110B is a large language model with 110b parameters and a 32k context length, designed for complex tasks requiring extensive data processing. It supports multiple quantized versions, offering flexibility in deployment across different hardware configurations.
References
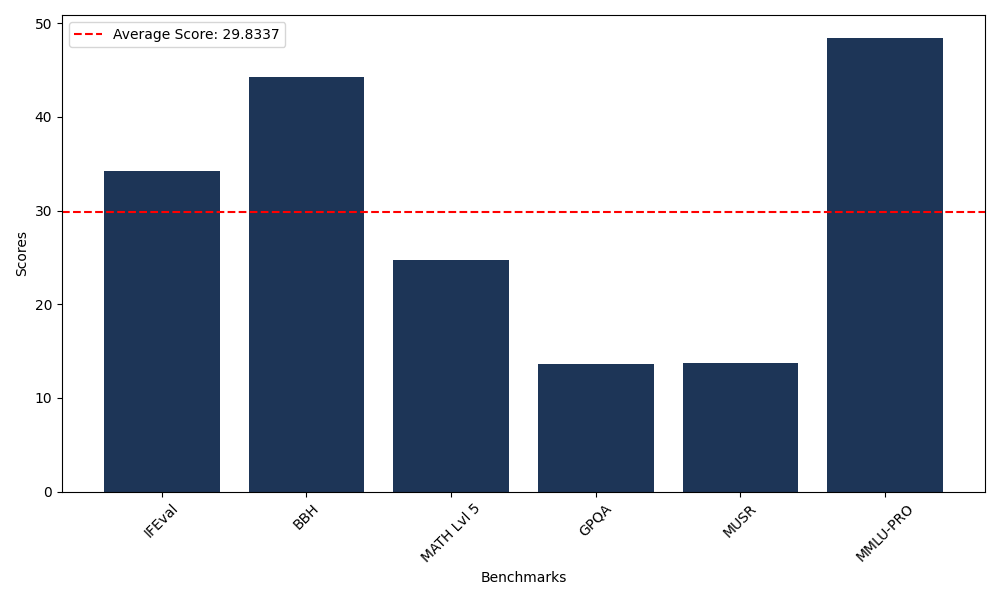
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 34.22 |
| Big Bench Hard (BBH) | 44.28 |
| Mathematical Reasoning Test (MATH Lvl 5) | 24.70 |
| General Purpose Question Answering (GPQA) | 13.65 |
| Multimodal Understanding and Reasoning (MUSR) | 13.71 |
| Massive Multitask Language Understanding (MMLU-PRO) | 48.45 |

Comments
No comments yet. Be the first to comment!
Leave a Comment