Qwen 32B - Model Details

Qwen 32B is a large language model developed by Qwen, a company, featuring 32b parameters. It is released under the Tongyi Qianwen Research License Agreement (TQRLA), Tongyi Qianwen License Agreement (TQ-LA), and Tongyi Qianwen License Agreement (TQ-LA), with a focus on improving human preference in chat models.
Description of Qwen 32B
Qwen1.5 is the beta version of Qwen2 a transformer-based decoder-only language model pretrained on a large amount of data. It includes 8 model sizes ranging from 0.5B to 72B with an MoE model of 14B featuring 2.7B activated parameters. Improvements over Qwen include enhanced performance in chat models multilingual support and a stable 32K context length. The model utilizes Transformer architecture with SwiGLU activation attention QKV bias group query attention and a tokenizer designed for multiple natural languages and code.
Parameters & Context Length of Qwen 32B
Qwen 32B features 32b parameters, placing it in the large model category capable of handling complex tasks but requiring significant computational resources. Its 32k context length enables efficient processing of extended texts, making it suitable for tasks involving lengthy documents or detailed reasoning, though it demands higher memory and processing power. The model’s parameter size and context length reflect a balance between capability and practicality, offering robust performance for demanding applications while acknowledging the trade-offs in resource usage.
- Parameter Size: 32b (Large models: 20B–70B, powerful for complex tasks but resource-intensive)
- Context Length: 32k (Long contexts: 8K–128K, ideal for extended texts but requires more resources)
Possible Intended Uses of Qwen 32B
Qwen 32B is a large language model with 32b parameters and a 32k context length, offering potential applications in areas like chatbot development, text generation with post-training, and multilingual applications. Its parameter size and context length suggest it could support complex tasks such as generating detailed responses, handling extended conversations, or adapting to multiple languages. However, these uses remain possible and require further exploration to confirm their effectiveness and suitability for specific scenarios. The model’s capabilities might also enable experimentation with advanced text generation techniques, but such possible applications would need rigorous testing and validation. The flexibility of its architecture and training data could open doors to innovative uses, though possible limitations or challenges may arise depending on the context.
- Intended Uses: chatbot development, text generation with post-training, multilingual applications
Possible Applications of Qwen 32B
Qwen 32B is a large language model with 32b parameters and a 32k context length, which could support possible applications in areas like advanced chatbot development, where its capacity to handle extended conversations might enable more natural interactions. It could also be used for possible text generation tasks requiring post-training customization, allowing tailored outputs for specific needs. Possible multilingual applications might benefit from its broad language support, enabling content creation or translation across diverse linguistic contexts. Additionally, possible uses in creative writing or data analysis could leverage its ability to process and generate complex, context-rich text. However, these possible applications require thorough evaluation to ensure alignment with specific requirements and constraints. Each application must be thoroughly evaluated and tested before use.
- Intended Uses: chatbot development, text generation with post-training, multilingual applications
Quantized Versions & Hardware Requirements of Qwen 32B
Qwen 32B's Q4 version requires a GPU with at least 24GB VRAM for optimal performance, making it suitable for systems with mid-to-high-end graphics cards. This quantized version balances precision and efficiency, allowing deployment on hardware that may not support larger models. Users should verify their GPU’s VRAM and compatibility before proceeding.
- fp16, q2, q3, q32, q4, q5, q6, q8
Conclusion
Qwen 32B is a transformer-based decoder-only language model with 32b parameters and a 32k context length, designed for complex tasks requiring extensive context understanding and generation. It balances performance and resource efficiency, making it suitable for advanced natural language processing applications.
References
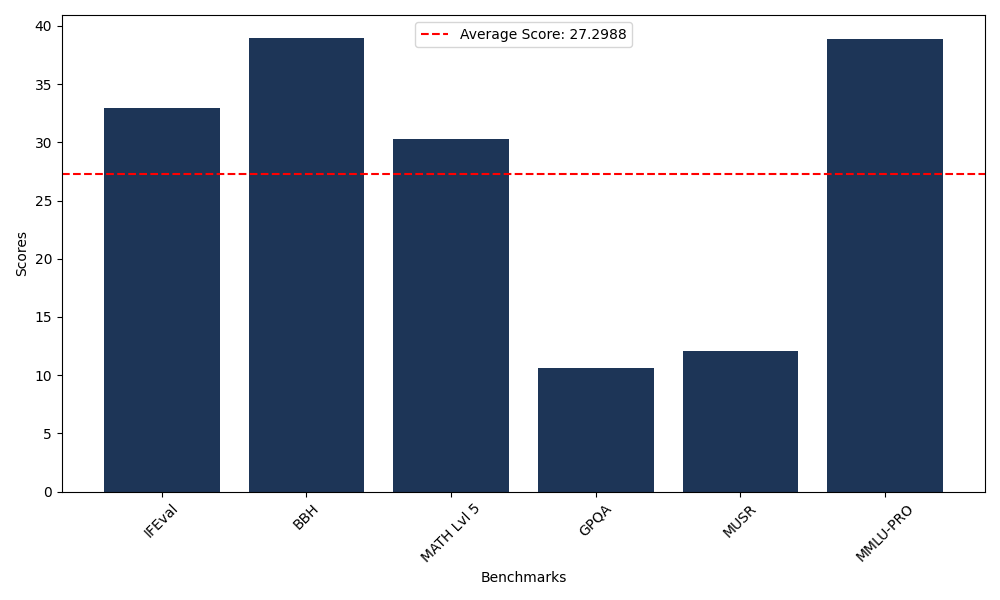
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 32.97 |
| Big Bench Hard (BBH) | 38.98 |
| Mathematical Reasoning Test (MATH Lvl 5) | 30.29 |
| General Purpose Question Answering (GPQA) | 10.63 |
| Multimodal Understanding and Reasoning (MUSR) | 12.04 |
| Massive Multitask Language Understanding (MMLU-PRO) | 38.89 |

Comments
No comments yet. Be the first to comment!
Leave a Comment