Qwen2.5 0.5B Base - Model Details

Qwen2.5 0.5B Base is a large language model developed by Alibaba Qwen (Qwenlm), a company with a strong focus on advancing AI research and applications. This model features 0.5b parameters, making it a compact yet powerful tool for various tasks. It is released under the Apache License 2.0, ensuring open access and flexibility for users. The model emphasizes enhanced factual knowledge and coding capabilities, making it suitable for scenarios requiring precision and technical expertise.
Description of Qwen2.5 0.5B Base
Qwen2.5 is the latest series of Qwen large language models, designed to enhance performance across multiple domains. It includes base language models and instruction-tuned models with parameter sizes ranging from 0.5B to 72B, offering flexibility for diverse applications. The series improves in knowledge accuracy, coding capabilities, mathematical reasoning, instruction following, long text generation, structured data understanding, and multilingual support. The 0.5B variant features 24 layers, RoPE architecture, and supports a 32,768-token context length, making it efficient for complex tasks while maintaining scalability.
Parameters & Context Length of Qwen2.5 0.5B Base
Qwen2.5 0.5B Base has 0.5b parameters, placing it in the small model category, which ensures fast and resource-efficient performance ideal for simple tasks. Its 32k context length allows handling long texts effectively, though it requires more resources compared to shorter contexts. This combination makes it suitable for applications needing moderate complexity while maintaining efficiency.
- Parameter Size: 0.5b
- Context Length: 32k
Possible Intended Uses of Qwen2.5 0.5B Base
Qwen2.5 0.5B Base is a versatile model with possible applications in general question answering and dialogue, where its multilingual support could enable interactions in chinese, german, italian, vietnamese, korean, spanish, french, portuguese, russian, thai, arabic, japanese, english. Its possible use in code generation and debugging might assist developers with writing or troubleshooting scripts, though further testing would be needed. The model’s possible role in multilingual text summarization could help condense content across languages, while its possible ability to analyze structured data and generate outputs might support tasks like report creation or data interpretation. These possible uses require thorough exploration to ensure effectiveness and alignment with specific needs.
- general question answering and dialogue
- code generation and debugging
- multilingual text summarization
- structured data analysis and output generation
Possible Applications of Qwen2.5 0.5B Base
Qwen2.5 0.5B Base has possible applications in general question answering and dialogue, where its multilingual support could enable interactions in chinese, german, italian, vietnamese, korean, spanish, french, portuguese, russian, thai, arabic, japanese, english. Its possible role in code generation and debugging might assist developers with writing or troubleshooting scripts, though further testing would be needed. The model’s possible use in multilingual text summarization could help condense content across languages, while its possible ability to analyze structured data and generate outputs might support tasks like report creation or data interpretation. These possible uses require thorough exploration to ensure effectiveness and alignment with specific needs.
- general question answering and dialogue
- code generation and debugging
- multilingual text summarization
- structured data analysis and output generation
Quantized Versions & Hardware Requirements of Qwen2.5 0.5B Base
Qwen2.5 0.5B Base with the q4 quantization offers a possible balance between precision and performance, requiring a GPU with at least 8GB VRAM for efficient operation, though exact needs depend on the model’s parameter count and workload. This version is possible to run on consumer-grade hardware, making it accessible for general tasks. For larger models, higher VRAM or multiple GPUs may be necessary.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
Qwen2.5 0.5B Base is a compact yet powerful large language model with 0.5b parameters, optimized for efficiency and versatility. It supports a 32k context length and multilingual tasks, making it suitable for coding, text generation, and structured data analysis.
References
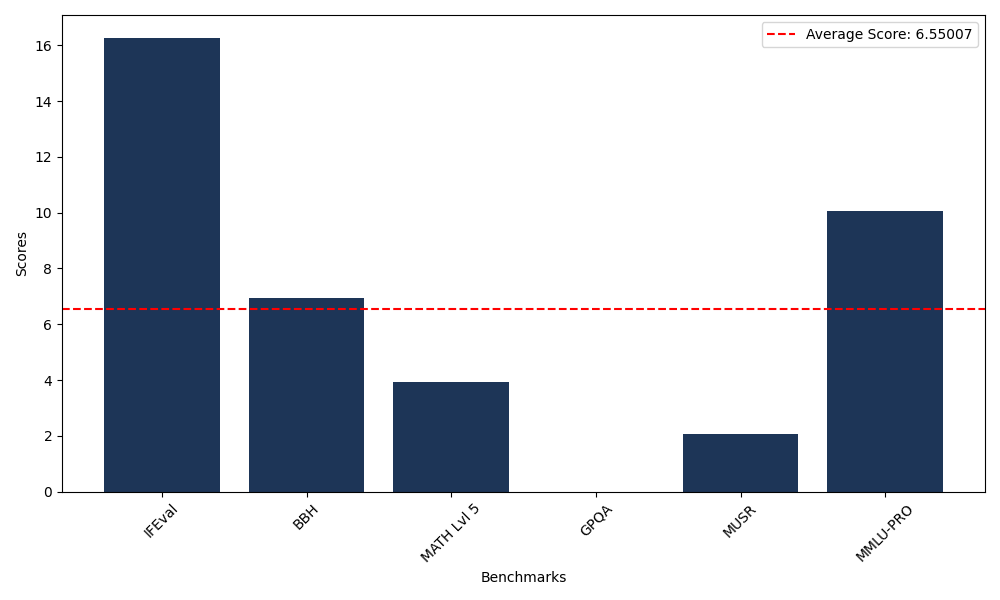
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 16.27 |
| Big Bench Hard (BBH) | 6.95 |
| Mathematical Reasoning Test (MATH Lvl 5) | 3.93 |
| General Purpose Question Answering (GPQA) | 0.00 |
| Multimodal Understanding and Reasoning (MUSR) | 2.08 |
| Massive Multitask Language Understanding (MMLU-PRO) | 10.06 |

Comments
No comments yet. Be the first to comment!
Leave a Comment