Qwen2.5 Coder 14B Instruct - Model Details

Qwen2.5 Coder 14B Instruct is a large language model developed by Alibaba Qwen, featuring 14b parameters and released under the Apache License 2.0. It is designed to excel in advanced code generation, reasoning, and repair across multiple programming languages.
Description of Qwen2.5 Coder 14B Instruct
Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models, featuring significant improvements in code generation, code reasoning, and code fixing. Trained on 5.5 trillion tokens of diverse data including source code, text-code grounding, and synthetic data, it supports long contexts up to 128K tokens and is optimized for real-world applications like Code Agents. As a state-of-the-art open-source codeLLM, it delivers coding capabilities comparable to GPT-4o, making it a powerful tool for developers and AI-driven code tasks.
Parameters & Context Length of Qwen2.5 Coder 14B Instruct
Qwen2.5 Coder 14B Instruct has 14b parameters, placing it in the mid-scale category of open-source LLMs, offering a balance between performance and resource efficiency for moderate complexity tasks. Its 128k context length falls into the very long context range, enabling it to handle extensive texts and complex reasoning but requiring significant computational resources. This combination makes it suitable for advanced coding tasks that demand both depth and breadth of understanding.
- Parameter Size: 14b
- Context Length: 128k
Possible Intended Uses of Qwen2.5 Coder 14B Instruct
Qwen2.5 Coder 14B Instruct is a model designed for code generation, code reasoning, and code fixing, with potential applications in the development of code agents. Possible uses include assisting developers in writing and optimizing code, analyzing and debugging complex programs, and supporting automated tasks that require logical reasoning. It could also be used to build tools that enhance productivity in software development workflows. However, these possible applications require further exploration to ensure they align with specific needs and constraints. The model’s capabilities in handling long contexts and multi-language tasks may open up additional possibilities for collaborative coding or advanced problem-solving scenarios.
- Intended Uses: code generation, code reasoning, code fixing, development of code agents
Possible Applications of Qwen2.5 Coder 14B Instruct
Qwen2.5 Coder 14B Instruct is a model with possible applications in areas such as automated code generation, logical reasoning for programming tasks, debugging and fixing code, and building tools for collaborative development. Possible uses might include streamlining repetitive coding workflows, enhancing code quality through automated analysis, or supporting developers in complex problem-solving scenarios. These possible applications could also extend to creating adaptive systems that assist with multi-language code integration or optimizing performance in software projects. However, each possible use requires thorough evaluation to ensure alignment with specific requirements and constraints.
- Possible Applications: code generation, code reasoning, code fixing, development of code agents
Quantized Versions & Hardware Requirements of Qwen2.5 Coder 14B Instruct
Qwen2.5 Coder 14B Instruct with the q4 quantization is a medium version that balances precision and performance, requiring a GPU with at least 24GB VRAM and 32GB system memory for optimal operation. This configuration ensures smooth execution while maintaining efficiency, though specific needs may vary based on workload. Possible hardware adjustments might be necessary for different tasks, and users should verify compatibility with their setup.
- Quantized Versions: fp16, q2, q3, q4, q5, q6, q8
Conclusion
Qwen2.5 Coder 14B Instruct is a large language model with 14b parameters and a 128k context length, optimized for advanced code generation, reasoning, and repair across multiple languages. It is released under the Apache License 2.0, making it an open-source tool for developers and researchers to explore applications like code agents and multi-language task handling.
References
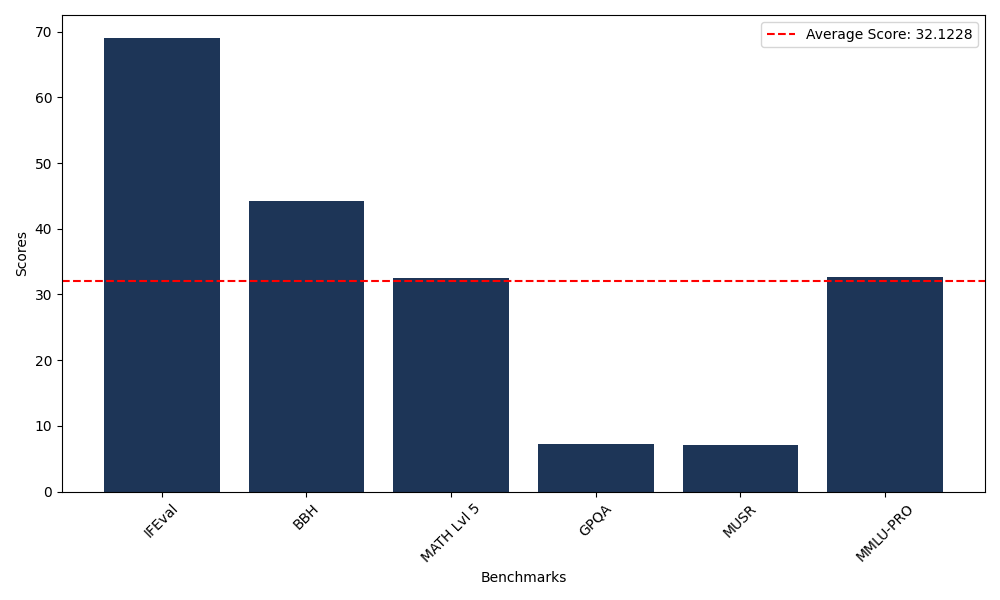
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 69.08 |
| Big Bench Hard (BBH) | 44.22 |
| Mathematical Reasoning Test (MATH Lvl 5) | 32.48 |
| General Purpose Question Answering (GPQA) | 7.27 |
| Multimodal Understanding and Reasoning (MUSR) | 7.03 |
| Massive Multitask Language Understanding (MMLU-PRO) | 32.66 |

Comments
No comments yet. Be the first to comment!
Leave a Comment