R1 1776 70B - Model Details

R1 1776 70B is a large language model developed by Perplexity Enterprise, a company focused on advancing AI capabilities. With 70b parameters, it is designed to handle complex tasks while emphasizing mitigating bias and censorship in multilingual models without compromising reasoning abilities. The model is released under the MIT License, allowing flexible use and modification.
Description of R1 1776 70B
An open-source large language model trained with Reflection-Tuning to detect and correct reasoning mistakes. Built on Llama 3.1 70B Instruct, it uses synthetic data from Glaive to enhance accuracy. The model outputs reasoning in <thinking> tags, final answers in <output> tags, and includes <reflection> for iterative corrections. This structured approach ensures transparency and reliability in complex reasoning tasks.
Parameters & Context Length of R1 1776 70B
The R1 1776 70B model features 70b parameters, placing it in the category of very large models optimized for complex tasks but requiring significant computational resources. Its 128k context length enables handling of extensive texts, making it ideal for long-form content while demanding substantial memory and processing power. This combination allows advanced reasoning and multilingual capabilities but necessitates careful resource management.
- Name: R1 1776 70B
- Parameter_Size: 70b
- Context_Length: 128k
- Implications: Best for complex tasks and very long texts, highly resource-intensive.
Possible Intended Uses of R1 1776 70B
The R1 1776 70B model is designed for tasks that require advanced reasoning and multilingual support, with possible applications in text generation, code writing, and answering questions. Its large parameter size and extended context length suggest possible utility in handling complex or lengthy inputs, though these possible uses would need validation through experimentation. The model’s focus on mitigating bias and censorship could also possibly enhance its reliability for open-ended tasks, but further research is required to confirm its effectiveness in specific scenarios. Possible deployment in creative writing, software development, or general knowledge retrieval might benefit from its structured output format, though real-world performance remains to be tested.
- text generation
- code writing
- answering questions
Possible Applications of R1 1776 70B
The R1 1776 70B model offers possible applications in areas such as multilingual content creation, where its focus on reducing bias could possibly enhance inclusivity. It might possibly support complex code generation tasks, leveraging its large parameter size for intricate programming challenges. Possible uses in academic or general knowledge Q&A systems could benefit from its structured reasoning outputs, though possible limitations in specific contexts require further exploration. Additionally, it possibly aids in analyzing long-form texts, given its extended context length, but possible performance variations across domains demand rigorous testing. Each application must be thoroughly evaluated and tested before deployment to ensure alignment with specific requirements.
- multilingual content creation
- complex code generation
- academic or general knowledge Q&A systems
- analysis of long-form texts
Quantized Versions & Hardware Requirements of R1 1776 70B
The R1 1776 70B model’s q4 quantized version, a possible balance between precision and performance, requires a GPU with at least 16GB VRAM for efficient operation, though higher VRAM may be needed for complex tasks. System memory should be at least 32GB, and adequate cooling and power supply are essential. This version reduces computational demands compared to full-precision models, making it possible to run on mid-range hardware, but performance may vary based on workload.
- fp16, q4, q8
Conclusion
The R1 1776 70B is a large language model developed by Perplexity Enterprise with 70b parameters, designed to mitigate bias and censorship in multilingual models while maintaining strong reasoning abilities. It operates under the MIT License, is open-source, and employs techniques like Reflection-Tuning and synthetic data to enhance accuracy and transparency in outputs.
References
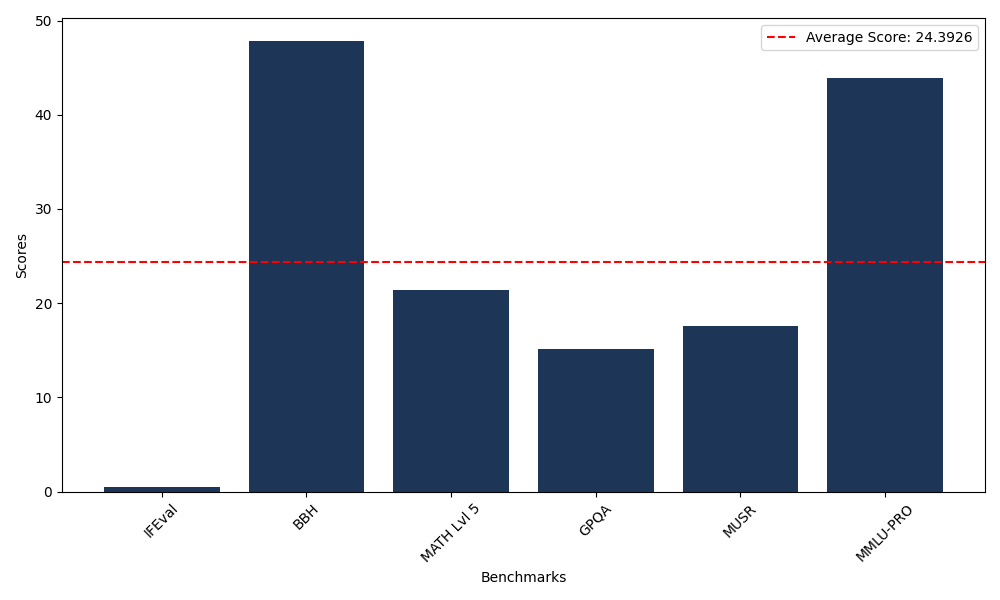
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 0.45 |
| Big Bench Hard (BBH) | 47.87 |
| Mathematical Reasoning Test (MATH Lvl 5) | 21.45 |
| General Purpose Question Answering (GPQA) | 15.10 |
| Multimodal Understanding and Reasoning (MUSR) | 17.54 |
| Massive Multitask Language Understanding (MMLU-PRO) | 43.95 |

Comments
No comments yet. Be the first to comment!
Leave a Comment