Reflection 70B - Model Details

Reflection 70B is a large language model with 70b parameters designed for advanced natural language processing tasks. Developed under the Llama 31 Community License Agreement (LLAMA-31-CCLA), it offers flexibility for research and development while adhering to specific usage guidelines. The model emphasizes scalability and performance, making it suitable for a wide range of applications. Its open licensing framework encourages collaboration within the community.
Description of Reflection 70B
Reflection Llama-3.1 70B is an open-source large language model trained with Reflection-Tuning to identify and correct reasoning errors during processing. It leverages synthetic data generated by Glaive to enhance its ability to refine outputs. The model structures its responses with
Parameters & Context Length of Reflection 70B
Reflection Llama-3.1 70B has 70b parameters, placing it in the very large models category, which enables it to handle highly complex tasks but requires significant computational resources. Its 4k context length falls under short contexts, making it effective for concise tasks but limiting its ability to process extended texts efficiently. The large parameter count allows for deeper reasoning and nuanced understanding, while the moderate context length ensures responsiveness without overwhelming system requirements.
- Parameter Size: 70b – Very Large Models (70B+) – Best for complex tasks, requiring significant resources.
- Context Length: 4k – Short Contexts (up to 4K Tokens) – Suitable for short tasks, limited in long texts.
Possible Intended Uses of Reflection 70B
Reflection Llama-3.1 70B is a large language model designed for advanced reasoning tasks, with possible applications in refining AI systems through iterative correction and structured output formats. Possible uses include enhancing reasoning in AI systems by leveraging its reflection capabilities, which allow for detecting and addressing errors during processing. Potential scenarios might involve improving error detection in responses by analyzing reasoning steps and generating corrections. Possible opportunities also exist for customizing models for specific tasks, as its design supports tailored adjustments while maintaining consistency with Llama 3.1 70B Instruct’s framework. These possible applications are still under exploration and require thorough investigation to ensure effectiveness and alignment with specific goals.
- Enhancing reasoning in AI systems
- Improving error detection in responses
- Customizing models for specific tasks with reflection capabilities
Possible Applications of Reflection 70B
Reflection Llama-3.1 70B is a large language model with possible applications in domains requiring advanced reasoning and iterative refinement. Possible uses include enhancing AI systems by integrating reflection-based error correction, which could improve reliability in dynamic environments. Potential scenarios might involve customizing models for specialized tasks through structured reasoning frameworks, allowing possible adaptability in technical or creative workflows. Possible opportunities also exist for refining responses in collaborative tools, where reflection capabilities could generate more accurate and context-aware outputs. These possible applications are still under exploration and require rigorous testing to ensure alignment with specific needs.
- Enhancing AI systems with reflection-based error correction
- Customizing models for specialized tasks through structured reasoning
- Refining responses in collaborative tools with iterative corrections
- Improving accuracy in technical or creative workflows
Quantized Versions & Hardware Requirements of Reflection 70B
Reflection Llama-3.1 70B’s medium q4 version balances precision and performance, requiring multiple GPUs with at least 48GB VRAM total for deployment, along with 32GB+ system memory and adequate cooling. This configuration ensures efficient execution while maintaining reasonable accuracy, though specific needs may vary based on workload and optimization. Possible applications for this version demand careful hardware evaluation to match computational capacity.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
Reflection Llama-3.1 70B is a large language model with 70b parameters designed for advanced reasoning tasks, utilizing Reflection-Tuning to detect and correct errors in responses through structured outputs like
References
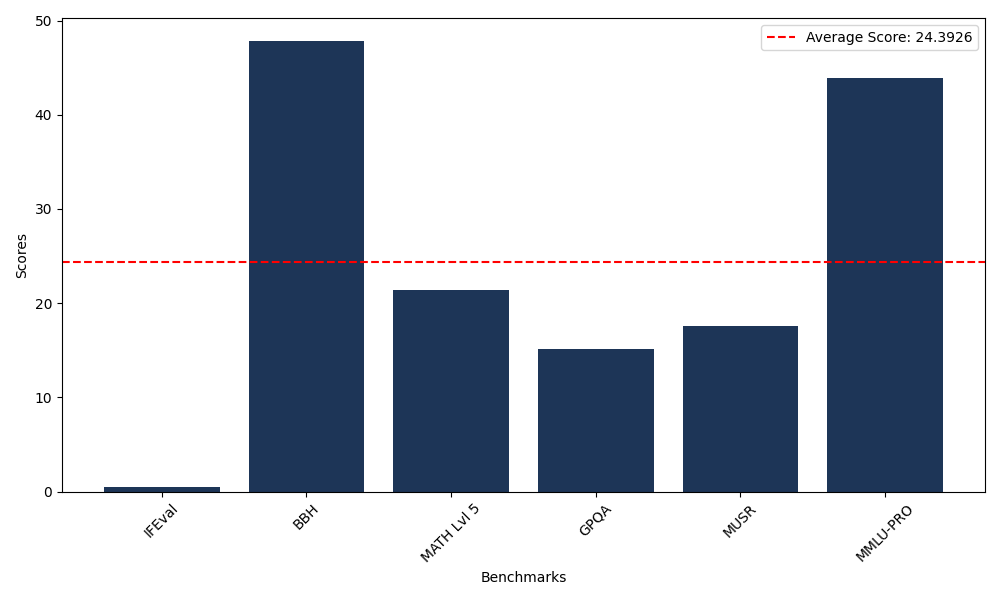
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 0.45 |
| Big Bench Hard (BBH) | 47.87 |
| Mathematical Reasoning Test (MATH Lvl 5) | 21.45 |
| General Purpose Question Answering (GPQA) | 15.10 |
| Multimodal Understanding and Reasoning (MUSR) | 17.54 |
| Massive Multitask Language Understanding (MMLU-PRO) | 43.95 |

Comments
No comments yet. Be the first to comment!
Leave a Comment