Smallthinker 3B - Model Details

Smallthinker 3B is a large language model developed by the community-driven maintainer Powerinfer. It features a parameter size of 3b, making it suitable for complex reasoning tasks. The model operates under the Qwen Research License Agreement (Qwen-RESEARCH), emphasizing its focus on optimizing long-chain COT reasoning to enhance logical and sequential problem-solving capabilities.
Description of Smallthinker 3B
SmallThinker-3B-preview is a fine-tuned model based on Qwen2.5-3B-Instruct, optimized for edge deployment on resource-constrained devices like phones using PowerServe. It acts as a fast draft model for the larger QwQ-32B-Preview, delivering a 70% speedup in llama.cpp. The model achieves improved performance in benchmarks such as AIME24 and GAOKAO2024 compared to Qwen2.5-3B-Instruct and GPT-4o, making it suitable for efficient and high-accuracy reasoning tasks on low-power hardware.
Parameters & Context Length of Smallthinker 3B
Smallthinker 3B has 3b parameters, placing it in the small model category, which prioritizes speed and efficiency for simpler tasks. Its 16k context length falls into the long context range, enabling it to handle extended sequences while requiring more resources than shorter contexts. This balance makes it suitable for applications needing moderate complexity without excessive computational demands.
- Name: Smallthinker 3B
- Parameter Size: 3b
- Context Length: 16k
- Implications: Small model efficiency with long-context capabilities, ideal for tasks requiring extended reasoning but limited by resource constraints.
Possible Intended Uses of Smallthinker 3B
Smallthinker 3B is a model designed for edge deployment on mobile devices, making it a possible candidate for applications where low-latency and on-device processing are critical. Its role as a draft model for QwQ-32B-Preview suggests it could be used to generate initial responses or simplify complex tasks before handing them to larger models, though this possible use case requires further testing. Additionally, its text generation capabilities for resource-constrained applications imply it might support tasks like lightweight content creation or real-time translation, but these possible applications need thorough evaluation. The model’s design prioritizes efficiency, which could make it suitable for scenarios where computational resources are limited, though its effectiveness in specific contexts remains to be confirmed.
- Intended Uses: edge deployment on mobile devices
- Intended Uses: draft model for qwq-32b-preview
- Intended Uses: text generation for resource-constrained applications
Possible Applications of Smallthinker 3B
Smallthinker 3B is a model with 3b parameters and a 16k context length, making it a possible candidate for applications requiring efficient processing and extended text handling. Its design possible supports edge deployment on mobile devices, enabling possible use in scenarios like real-time text generation or lightweight AI assistants where low latency is critical. As a possible draft model for larger systems, it could possible assist in preprocessing tasks before more complex models take over, though this possible role needs further validation. Its possible suitability for resource-constrained environments suggests it might possible be used in applications like educational tools or interactive content creation, but these possible uses require thorough testing. Each application must be thoroughly evaluated and tested before use.
- Smallthinker 3B: edge deployment on mobile devices
- Smallthinker 3B: real-time text generation for lightweight tasks
- Smallthinker 3B: preprocessing for larger models
- Smallthinker 3B: educational or interactive content creation
Quantized Versions & Hardware Requirements of Smallthinker 3B
Smallthinker 3B’s medium q4 version requires a GPU with at least 12GB VRAM for efficient operation, making it suitable for devices with moderate computational resources. This quantization balances precision and performance, allowing the model to run on systems with 8GB–16GB VRAM while maintaining reasonable speed. A 32GB RAM system is recommended, along with adequate cooling and a stable power supply. The fp16, q4, and q8 quantized versions are available, each offering different trade-offs between accuracy and resource usage.
- Smallthinker 3B: fp16, q4, q8
Conclusion
Smallthinker 3B is a 3b-parameter model with a 16k context length, offering fp16, q4, and q8 quantized versions for efficient deployment. It is optimized for edge computing, draft modeling, and resource-constrained applications, making it suitable for scenarios requiring balanced performance and accessibility.
References
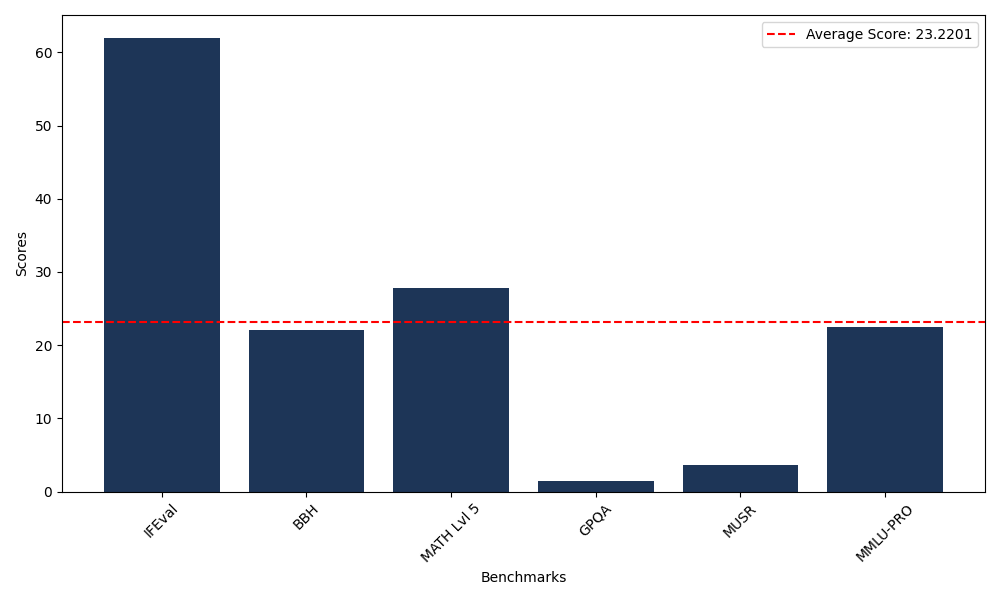
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 62.00 |
| Big Bench Hard (BBH) | 22.06 |
| Mathematical Reasoning Test (MATH Lvl 5) | 27.79 |
| General Purpose Question Answering (GPQA) | 1.45 |
| Multimodal Understanding and Reasoning (MUSR) | 3.59 |
| Massive Multitask Language Understanding (MMLU-PRO) | 22.42 |

Comments
No comments yet. Be the first to comment!
Leave a Comment