Smollm 1.7B Base - Model Details

Smollm 1.7B Base is a large language model developed by Hugging Face Smol Models Research Enterprise with 1.7b parameters. It operates under the Apache License 2.0 and emphasizes optimizing data curation and architecture to deliver strong performance in small to medium-sized models. Its design prioritizes efficiency and adaptability for diverse applications.
Description of Smollm 1.7B Base
SmolLM is a series of state-of-the-art small language models available in three sizes: 135M, 360M, and 1.7B parameters. These models are trained on Cosmo-Corpus, a high-quality dataset curated from three sources: Cosmopedia v2 (28B tokens of synthetic textbooks and stories generated by Mixtral), Python-Edu (4B tokens of educational Python samples from The Stack), and FineWeb-Edu (220B tokens of deduplicated educational web samples from FineWeb). SmolLM models have demonstrated strong performance in benchmarks testing common sense reasoning and world knowledge, outperforming others in their size categories. Their design emphasizes efficiency and effectiveness for applications requiring compact yet powerful language models.
Parameters & Context Length of Smollm 1.7B Base
Smollm 1.7B Base is a 1.7b parameter model with a 4k context length, placing it in the small models category (up to 7B parameters) and short contexts (up to 4K tokens). This configuration ensures fast and resource-efficient performance, making it ideal for simple tasks and short-text applications, though it may struggle with extended or highly complex sequences. Its design balances efficiency and accessibility, prioritizing usability over extreme scale.
- Name: Smollm 1.7B Base
- Parameter Size: 1.7b
- Context Length: 4k
Possible Intended Uses of Smollm 1.7B Base
Smollm 1.7B Base is a versatile model with 1.7b parameters and a 4k context length, offering possible applications in areas like text generation, code generation, and educational content creation. Its design suggests it could be used for crafting concise narratives, assisting with programming tasks, or developing learning materials, though these possible uses require further validation. The model’s size and context length make it suitable for tasks where efficiency and accessibility are prioritized, but its effectiveness in specific scenarios remains to be thoroughly tested. Possible use cases might include generating summaries, writing scripts, or creating interactive educational modules, though these ideas need careful exploration.
- text generation
- code generation
- educational content creation
Possible Applications of Smollm 1.7B Base
Smollm 1.7B Base is a 1.7b parameter model with a 4k context length, offering possible applications in areas like text generation, code generation, and educational content creation. Its design suggests it could be used for possible tasks such as drafting creative writing, assisting with programming challenges, or developing interactive learning materials, though these possible uses require further validation. The model’s size and context length make it suitable for possible scenarios where efficiency and accessibility are prioritized, but its effectiveness in specific contexts remains to be thoroughly tested. Possible applications might also include generating concise summaries or creating structured documentation, though these ideas need careful exploration.
- text generation
- code generation
- educational content creation
Quantized Versions & Hardware Requirements of Smollm 1.7B Base
Smollm 1.7B Base's medium q4 version requires a GPU with at least 8GB VRAM (up to 16GB for optimal performance) and 32GB of system memory, making it suitable for devices with moderate hardware capabilities. This balance of precision and performance ensures efficient execution while maintaining reasonable accuracy. The available quantized versions include fp16, q2, q3, q4, q5, q6, q8.
Conclusion
Smollm 1.7B Base is a 1.7b parameter model with a 4k context length, part of the SmolLM series trained on the high-quality Cosmo-Corpus dataset. It emphasizes optimized data curation and architecture for strong performance in small to medium-sized tasks, demonstrating promising results in benchmarks for common sense reasoning and world knowledge.
References
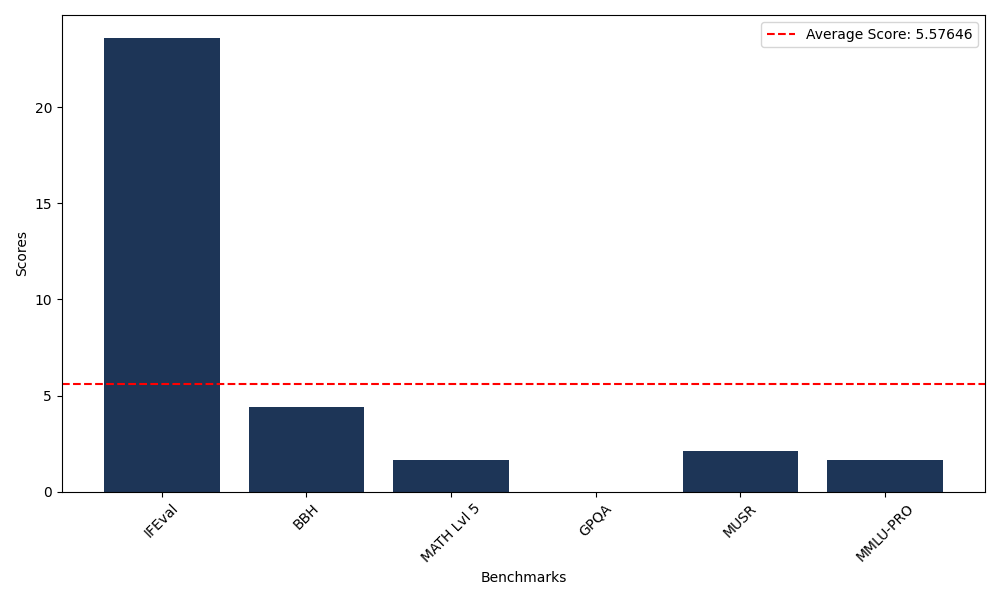
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 23.62 |
| Big Bench Hard (BBH) | 4.41 |
| Mathematical Reasoning Test (MATH Lvl 5) | 1.66 |
| General Purpose Question Answering (GPQA) | 0.00 |
| Multimodal Understanding and Reasoning (MUSR) | 2.13 |
| Massive Multitask Language Understanding (MMLU-PRO) | 1.64 |

Comments
No comments yet. Be the first to comment!
Leave a Comment