Starcoder 7B Base - Model Details

Starcoder 7B Base is a large language model developed by Bigcodeproject, a non-profit organization, featuring 7b parameters. It is released under the BigCode Open Rail-M V1 License Agreement and is designed to excel in coding tasks with extensive knowledge of programming languages.
Description of Starcoder 7B Base
Starcoder 7B Base is a 7B parameter model trained on 17 programming languages from The Stack v2, excluding opt-out requests. It employs Grouped Query Attention and features a 16,384 token context window with a 4,096 token sliding window attention. The model was trained using the Fill-in-the-Middle objective on 3.5+ trillion tokens, making it highly effective for coding tasks and programming language understanding.
Parameters & Context Length of Starcoder 7B Base
Starcoder 7B Base has 7b parameters, placing it in the mid-scale range of open-source LLMs, offering a balance between performance and resource efficiency for coding tasks. Its 16k token context length falls into the long context category, enabling it to process extended codebases or detailed instructions while requiring more computational resources than shorter contexts. This combination makes it well-suited for complex programming challenges without excessive demand on hardware.
- Parameter Size: 7b
- Context Length: 16k
Possible Intended Uses of Starcoder 7B Base
Starcoder 7B Base is a model with 7b parameters designed for coding tasks, and its possible uses include generating code based on contextual prompts, which could be explored for tasks like script creation or algorithm design. It may also be possible to fine-tune the model for specific programming challenges, such as optimizing code for particular frameworks or languages, though this would require testing and adaptation. The model’s flexibility to run on CPU/GPU with varying precision configurations suggests possible applications in environments with different hardware constraints, though performance trade-offs would need evaluation. These possible uses are not guaranteed and require thorough investigation to determine their effectiveness and suitability for specific scenarios.
- code generation based on contextual prompts
- fine-tuning for specific programming tasks
- running on cpu/gpu with various precision configurations
Possible Applications of Starcoder 7B Base
Starcoder 7B Base is a model with 7b parameters and a 16k token context length, making it possible to support applications like generating code snippets from natural language prompts, which could be explored for scripting or prototyping. It may also be possible to adapt the model for code optimization tasks, such as refactoring or improving efficiency in specific programming environments. The model’s flexibility to run on CPU/GPU with varying precision settings suggests possible use cases in educational tools or lightweight development environments where resource constraints are a factor. Additionally, it might be possible to leverage its programming language knowledge for creating domain-specific code assistants, though this would require tailored training and validation. Each of these possible applications requires thorough evaluation and testing to ensure alignment with specific needs and constraints.
- code generation based on contextual prompts
- fine-tuning for specific programming tasks
- running on cpu/gpu with various precision configurations
- domain-specific code assistance tools
Quantized Versions & Hardware Requirements of Starcoder 7B Base
Starcoder 7B Base with the medium q4 quantization is possible to run on a GPU with at least 16GB VRAM, requiring a multi-core CPU and 32GB+ system memory, with adequate cooling and power supply. This version balances precision and performance, making it possible for users with mid-range hardware to deploy the model for coding tasks. However, specific requirements may vary based on workload and configuration.
fp16, q2, q3, q4, q5, q6, q8
Conclusion
Starcoder 7B Base is a 7b parameter model developed by Bigcodeproject, a non-profit, designed for coding tasks with a 16k token context length and support for multiple quantization options. It is released under the BigCode Open Rail-M V1 License and can be deployed on CPU/GPU with varying precision configurations, making it adaptable for diverse programming applications.
References
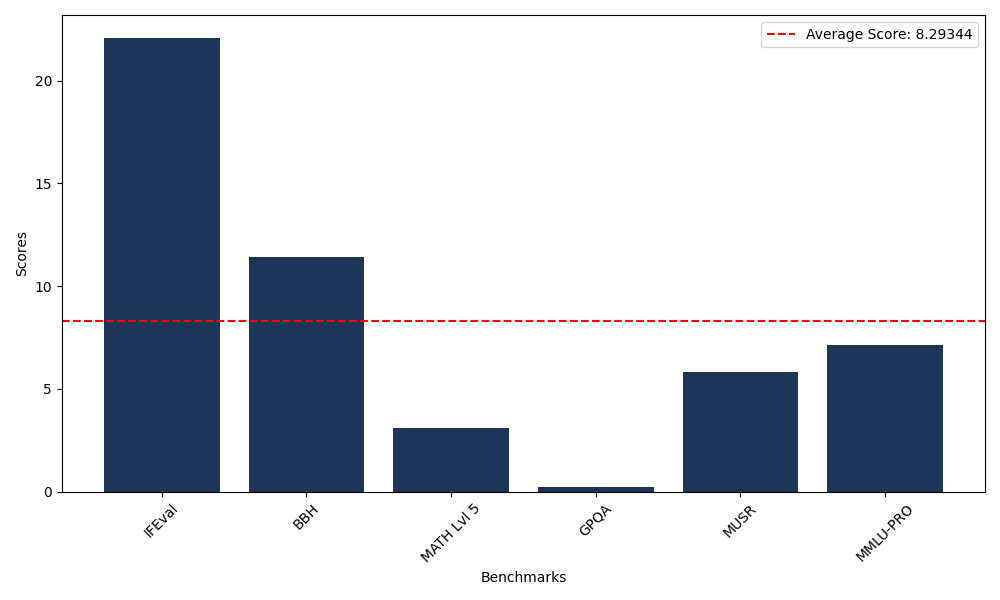
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 22.09 |
| Big Bench Hard (BBH) | 11.40 |
| Mathematical Reasoning Test (MATH Lvl 5) | 3.10 |
| General Purpose Question Answering (GPQA) | 0.22 |
| Multimodal Understanding and Reasoning (MUSR) | 5.82 |
| Massive Multitask Language Understanding (MMLU-PRO) | 7.14 |

Comments
No comments yet. Be the first to comment!
Leave a Comment