Starcoder2 7B - Model Details

Starcoder2 7B is a large language model developed by the non-profit Bigcodeproject, featuring a parameter size of 7b. It operates under the BigCode-Open-RAIL-M-v1 license, emphasizing transparency in its training process. The model offers three distinct sizes, delivering strong performance while prioritizing openness and accessibility in its development.
Description of Starcoder2 7B
Starcoder2 7B is a 7B parameter model trained on 17 programming languages from The Stack v2, leveraging Grouped Query Attention for efficient processing. It supports a 16,384 token context window with a 4,096 token sliding window, enabling complex code analysis. Trained on 3.5+ trillion tokens using the Fill-in-the-Middle objective, it excels in code generation and understanding across diverse programming languages.
Parameters & Context Length of Starcoder2 7B
Starcoder2 7B is a 7b parameter model designed for code generation and understanding, offering a 16k context length that enables it to process extended sequences of text. The 7b parameter size places it in the mid-scale category, balancing performance and resource efficiency for moderate complexity tasks, while the 16k context length allows for handling long documents or codebases, though it requires more computational resources than shorter contexts. This combination makes it well-suited for tasks requiring both depth and breadth in text analysis.
- Parameter Size: 7b
- Context Length: 16k
Possible Intended Uses of Starcoder2 7B
Starcoder2 7B is a 7b parameter model designed for code generation and understanding, with possible applications in areas like code completion and translation between programming languages. Its ability to process 16k context length suggests it could support possible uses such as generating code snippets from natural language descriptions, though these possible applications would require further testing to confirm their effectiveness. The model’s focus on transparency and multi-language support opens possible opportunities for developers working across diverse coding environments, but possible limitations may arise depending on the specific task or dataset. Exploring these possible uses would involve careful evaluation to ensure alignment with project goals and technical constraints.
- code completion and generation
- code translation between programming languages
- generating code snippets based on natural language descriptions
Possible Applications of Starcoder2 7B
Starcoder2 7B is a 7b parameter model designed for code generation and understanding, with possible applications in areas like code completion, translation between programming languages, and generating code snippets from natural language descriptions. Its 16k context length suggests it could support possible uses in tasks requiring extended text analysis, such as multi-file project handling or complex code structure interpretation. Possible scenarios might include automating repetitive coding tasks or assisting with cross-language development, though these possible applications would require careful validation to ensure alignment with specific project needs. Possible benefits could arise from its transparency and multi-language support, but possible limitations may depend on the complexity of the input or the specific coding environment.
- code completion and generation
- code translation between programming languages
- generating code snippets based on natural language descriptions
- assisting with multi-file project analysis or complex code structures
Each application must be thoroughly evaluated and tested before use.
Quantized Versions & Hardware Requirements of Starcoder2 7B
Starcoder2 7B’s medium q4 version requires a GPU with at least 16GB VRAM for efficient operation, making it suitable for systems with mid-range graphics cards. This quantization balances precision and performance, reducing memory usage while maintaining reasonable accuracy. A system with at least 32GB RAM and adequate cooling is recommended for stable execution.
fp16, q2, q3, q4, q5, q6, q8
Conclusion
Starcoder2 7B is a 7b parameter large language model developed by the non-profit Bigcodeproject, trained on 17 programming languages from The Stack v2 with a 16k token context length and 3.5+ trillion tokens using the Fill-in-the-Middle objective, making it highly effective for code generation and cross-language understanding. Its BigCode-Open-RAIL-M-v1 license ensures transparency and accessibility, while its mid-scale parameter size balances performance and resource efficiency for diverse coding tasks.
References
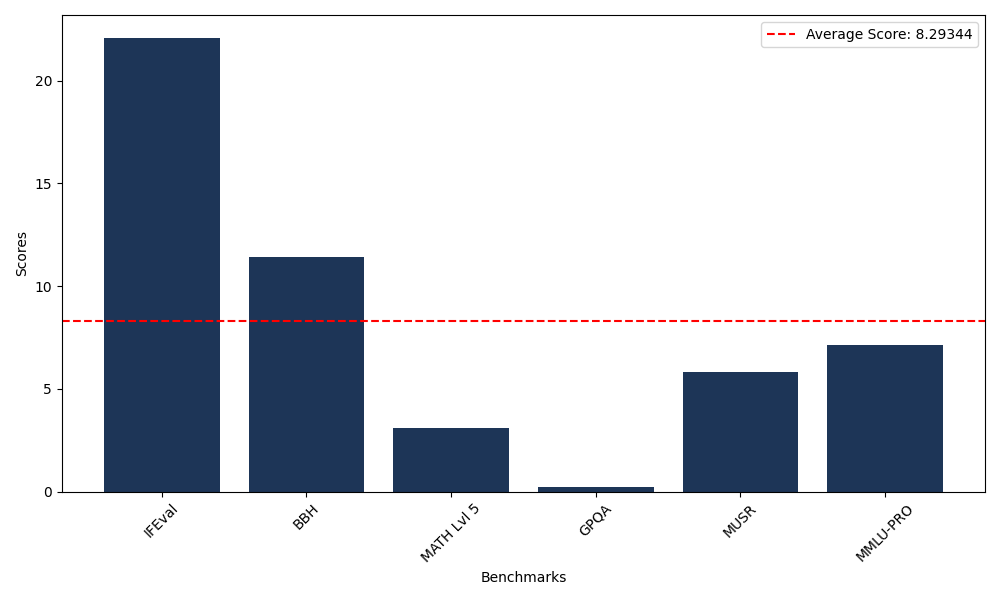
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 22.09 |
| Big Bench Hard (BBH) | 11.40 |
| Mathematical Reasoning Test (MATH Lvl 5) | 3.10 |
| General Purpose Question Answering (GPQA) | 0.22 |
| Multimodal Understanding and Reasoning (MUSR) | 5.82 |
| Massive Multitask Language Understanding (MMLU-PRO) | 7.14 |

Comments
No comments yet. Be the first to comment!
Leave a Comment