Tinyllama 1.1B

Tinyllama 1.1B is a large language model developed by the university-affiliated project Tinyllama, featuring 1.1 billion parameters. It is designed with a focus on optimized computational efficiency, leveraging FlashAttention to enhance performance while maintaining resource constraints.
Description of Tinyllama 1.1B
Tinyllama 1.1B is a large language model pre-trained on 3 trillion tokens using the same architecture and tokenizer as Llama 2, ensuring compatibility with open-source projects. It is optimized for low computational and memory footprints, making it suitable for resource-constrained applications. The model was trained on 16 A100-40G GPUs over 90 days, with a chat variant fine-tuned on synthetic dialogues and aligned with GPT-4-ranked data to enhance conversational performance. Maintained by the Tinyllama project, it balances efficiency and capability for diverse use cases.
Parameters & Context Length of Tinyllama 1.1B
Tinyllama 1.1B has 1.1 billion parameters, placing it in the small model category, which ensures fast and resource-efficient performance for tasks requiring moderate complexity. Its context length of 2,000 tokens falls within the short context range, making it suitable for concise tasks but limiting its ability to handle extended sequences. This combination prioritizes accessibility and speed, ideal for applications where computational resources are constrained. The model’s design balances efficiency with functionality, offering a practical solution for users seeking performance without excessive demands.
- Parameter Size: 1.1b
- Context Length: 2k
Possible Intended Uses of Tinyllama 1.1B
Tinyllama 1.1B is a compact model with 1.1 billion parameters and a 2,000-token context length, making it a possible candidate for applications where computational efficiency and low resource consumption are critical. Its design suggests possible use in edge computing devices with limited processing power, where lightweight models can operate without excessive latency. It could also serve as a possible solution for mobile applications requiring minimal memory footprint, enabling faster deployment on devices with constrained hardware. Additionally, its conversational fine-tuning opens possible opportunities for chatbots and virtual assistants that prioritize responsiveness over extensive contextual understanding. However, these uses remain speculative and require further validation to ensure compatibility with specific tasks or environments.
- edge computing devices with limited resources
- mobile applications requiring lightweight models
- conversational chatbots and virtual assistants
Possible Applications of Tinyllama 1.1B
Tinyllama 1.1B is a compact model with 1.1 billion parameters and a 2,000-token context length, making it a possible choice for applications where computational efficiency and low resource consumption are prioritized. Its design suggests possible use in edge computing devices with limited processing power, where lightweight models can operate without excessive latency. It could also serve as a possible solution for mobile applications requiring minimal memory footprint, enabling faster deployment on devices with constrained hardware. Additionally, its conversational fine-tuning opens possible opportunities for chatbots and virtual assistants that prioritize responsiveness over extensive contextual understanding. These applications remain speculative and require thorough evaluation to ensure alignment with specific use cases. Each application must be thoroughly evaluated and tested before use.
- edge computing devices with limited resources
- mobile applications requiring lightweight models
- conversational chatbots and virtual assistants
- virtual assistants with real-time interaction capabilities
Quantized Versions & Hardware Requirements of Tinyllama 1.1B
Tinyllama 1.1B with the medium q4 quantization requires a GPU with at least 8GB VRAM or a multi-core CPU, making it possible to run on devices with moderate hardware. This version balances precision and performance, suitable for systems with limited resources. System memory should be at least 32GB to ensure smooth operation.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
Tinyllama 1.1B is a compact large language model with 1.1 billion parameters and a 2,000-token context length, optimized for computational efficiency using FlashAttention. It is designed for applications requiring low resource consumption, such as edge devices, mobile apps, and conversational chatbots, with multiple quantized versions available to suit different hardware capabilities.
References
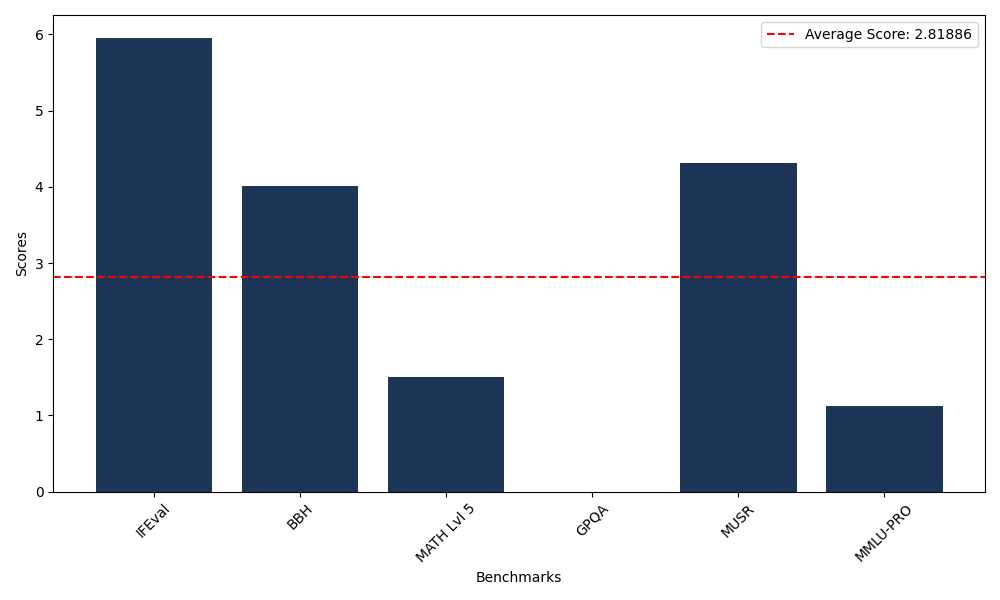
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 5.96 |
| Big Bench Hard (BBH) | 4.01 |
| Mathematical Reasoning Test (MATH Lvl 5) | 1.51 |
| General Purpose Question Answering (GPQA) | 0.00 |
| Multimodal Understanding and Reasoning (MUSR) | 4.31 |
| Massive Multitask Language Understanding (MMLU-PRO) | 1.12 |