Wizardlm 70B - Model Details

Wizardlm 70B is a large language model developed by Wizardlm, an organization, featuring 70b parameters. It operates under the Llama 2 Community License Agreement (LLAMA-2-CLA).
Description of Wizardlm 70B
WizardLM is a series of large language models designed to follow complex instructions, with versions like 70B, 13B, 30B, and 7B. It adopts the Vicuna prompt format for multi-turn conversations and supports tasks such as coding, mathematical problem-solving, and general question-answering. The models are based on the Llama 2 framework and have been optimized for performance on benchmarks like HumanEval and GSM8K.
Parameters & Context Length of Wizardlm 70B
Wizardlm 70B has 70b parameters, placing it in the very large models category, which means it excels at complex tasks but requires significant computational resources. Its 4k context length falls under short contexts, making it suitable for concise tasks but limiting its ability to process extended texts. The high parameter count enables advanced reasoning and multitasking, while the moderate context length balances efficiency with practicality for most applications.
- Name: Wizardlm 70B
- Parameter Size: 70b
- Context Length: 4k
- Implications: Powerful for complex tasks, resource-intensive; suitable for short to moderate-length inputs.
Possible Intended Uses of Wizardlm 70B
Wizardlm 70B is a large language model with 70b parameters and a 4k context length, designed to support a range of possible applications. Its high parameter count suggests it could be used for coding assistance, where it might help generate or debug code, though this would require testing to confirm effectiveness. It could also be explored for mathematical problem solving, potentially aiding in complex calculations or logical reasoning tasks, but further evaluation would be needed. General question answering is another possible use, as the model might provide detailed responses to diverse queries, though its accuracy and reliability would need thorough validation. These possible uses are not guaranteed and would require careful investigation to ensure they align with specific needs.
- Intended Uses: coding assistance, mathematical problem solving, general question answering
Possible Applications of Wizardlm 70B
Wizardlm 70B is a large language model with 70b parameters and a 4k context length, which could be used for possible applications such as coding assistance, where it might help generate or refine code, though this would require testing to confirm reliability. It could also be explored for mathematical problem solving, potentially supporting complex calculations or logical reasoning tasks, but further validation would be necessary. General question answering is another possible use, as the model might provide detailed responses to diverse queries, though its accuracy would need thorough assessment. Additionally, technical documentation could be a possible application, where it might assist in creating or organizing detailed explanations, though this would require careful evaluation. Each of these possible applications must be thoroughly evaluated and tested before deployment to ensure suitability and effectiveness.
- Possible Applications: coding assistance, mathematical problem solving, general question answering, technical documentation
Quantized Versions & Hardware Requirements of Wizardlm 70B
Wizardlm 70B in its medium q4 version requires multiple GPUs with at least 48GB VRAM total for deployment, along with 32GB system RAM and adequate cooling to handle the computational load. This configuration ensures the model can run efficiently while balancing precision and performance. The q4 quantization reduces memory usage compared to higher-precision versions like fp16, making it more accessible for systems with sufficient GPU resources.
- Quantized Versions: fp16, q2, q3, q4, q5, q6, q8
Conclusion
Wizardlm 70B is a large language model with 70b parameters and a 4k context length, developed by Wizardlm and based on the Llama 2 framework, designed for tasks like coding, mathematical problem-solving, and general question-answering. It operates under the Llama 2 Community License Agreement (LLAMA-2-CLA) and is part of a series including 7B, 13B, 30B, and 70B versions, optimized for benchmarks such as HumanEval and GSM8K.
References
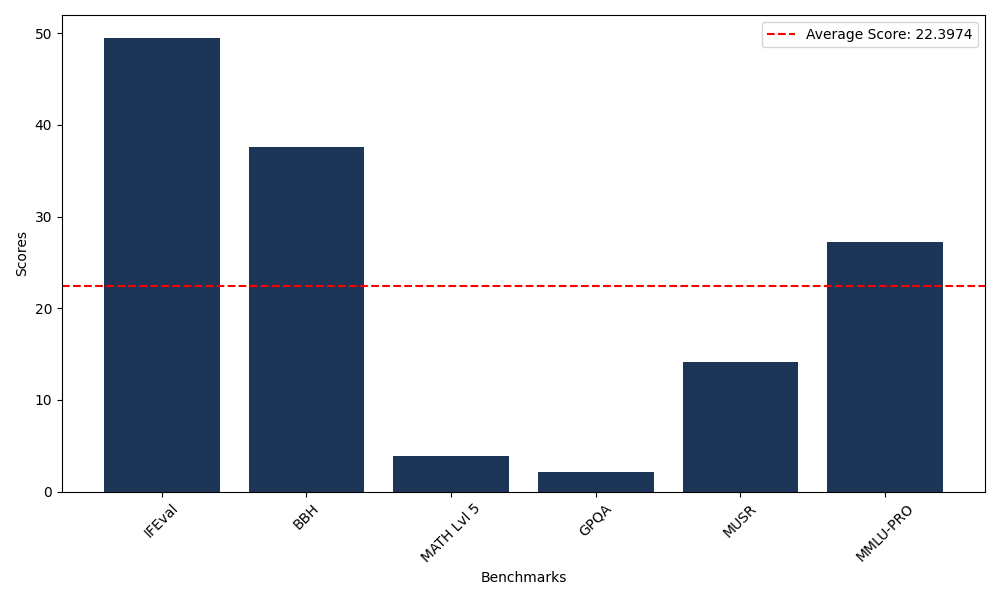
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 49.51 |
| Big Bench Hard (BBH) | 37.54 |
| Mathematical Reasoning Test (MATH Lvl 5) | 3.93 |
| General Purpose Question Answering (GPQA) | 2.13 |
| Multimodal Understanding and Reasoning (MUSR) | 14.09 |
| Massive Multitask Language Understanding (MMLU-PRO) | 27.18 |

Comments
No comments yet. Be the first to comment!
Leave a Comment