Wizardlm2 7B - Model Details

Wizardlm2 7B is a large language model developed by Dreamgen, a company, featuring 7b parameters. It is released under the Apache License 2.0 (Apache-2.0), Apache License 2.0 (Apache-2.0). The model, part of Microsoft's WizardLM-2 series, excels in complex chat tasks and multilingual capabilities.
Description of Wizardlm2 7B
WizardLM-2 is a next-generation large language model series developed by Microsoft, featuring three variants: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B. The 8x22B model demonstrates highly competitive performance against leading proprietary models, the 70B model achieves top-tier reasoning capabilities, and the 7B model is the fastest while maintaining comparable performance to larger models. The series excels in complex chat tasks, multilingual support, reasoning, and agent-related functions, making it a versatile choice for various applications.
Parameters & Context Length of Wizardlm2 7B
WizardLM-2 7B is a large language model with 7b parameters, placing it in the small model category, which ensures fast and resource-efficient performance ideal for simple tasks. Its context length of 4k tokens falls into the short context range, making it suitable for concise interactions but limiting its ability to handle extended texts. The model’s design balances accessibility and efficiency, prioritizing speed over handling very long sequences.
- Parameter Size: 7b
- Context Length: 4k
Possible Intended Uses of Wizardlm2 7B
WizardLM-2 7B is a large language model designed for a range of tasks, with possible applications in complex chat interactions, multilingual processing, reasoning and agent-based functions, coding, math problem solving, and writing tasks. These possible uses highlight its versatility but require further investigation to determine their effectiveness in specific scenarios. The model’s 7b parameter size and 4k context length suggest it could handle tasks needing moderate computational resources, though its performance in these areas remains to be fully validated. Potential uses may include supporting collaborative workflows, enhancing language translation, or assisting with structured problem-solving, but thorough testing is necessary to confirm their feasibility.
- complex chat
- multilingual tasks
- reasoning and agent tasks
- coding
- math problem solving
- writing tasks
Possible Applications of Wizardlm2 7B
WizardLM-2 7B is a large language model with possible applications in complex chat interactions, multilingual tasks, coding, and math problem solving. These possible uses leverage its 7b parameter size and 4k context length, which may enable efficient handling of tasks requiring moderate computational resources. While the model’s design suggests potential for supporting collaborative workflows, language translation, or structured problem-solving, these possible applications must be thoroughly evaluated to ensure suitability for specific contexts. The model’s capabilities in reasoning and agent tasks also present possible opportunities for enhancing task automation, though further testing is essential. Each application must be thoroughly evaluated and tested before use.
- complex chat
- multilingual tasks
- coding
- math problem solving
Quantized Versions & Hardware Requirements of Wizardlm2 7B
WizardLM-2 7B’s medium q4 version requires a GPU with at least 16GB VRAM for optimal performance, making it suitable for systems with mid-range graphics cards. This quantization balances precision and efficiency, allowing the model to run on hardware with 12GB–24GB VRAM while maintaining reasonable speed. System memory should be at least 32GB, and adequate cooling and power supply are recommended. The q4 version is a possible choice for users seeking a balance between resource usage and model quality.
- fp16, q2, q3, q4, q5, q6, q8
Conclusion
WizardLM-2 7B is a 7b-parameter large language model developed by Microsoft, designed for complex chat, multilingual tasks, reasoning, and agent functions with a 4k context length. Its balance of efficiency and performance makes it suitable for diverse applications while requiring careful evaluation for specific use cases.
References
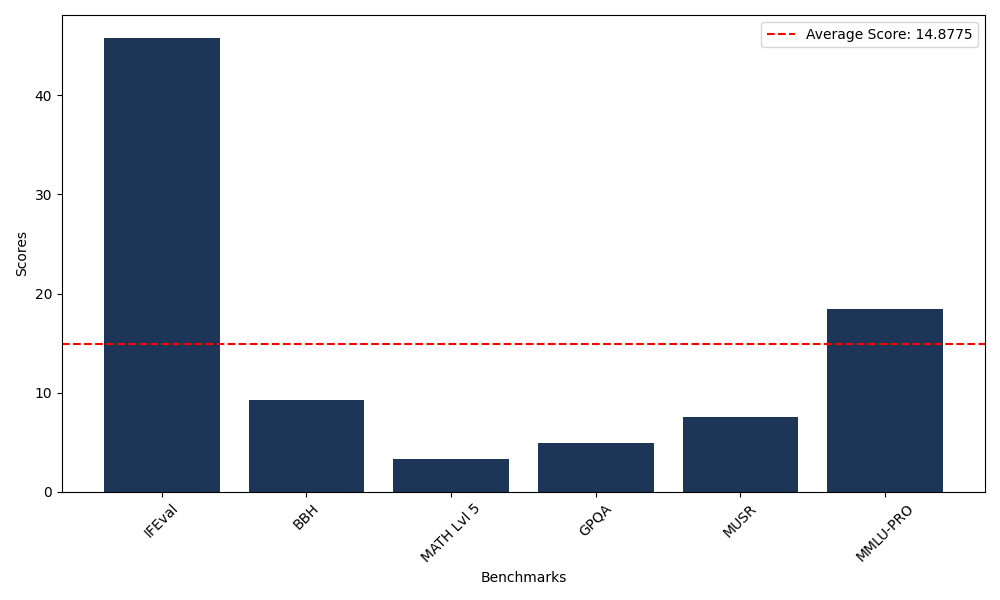
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 45.83 |
| Big Bench Hard (BBH) | 9.21 |
| Mathematical Reasoning Test (MATH Lvl 5) | 3.32 |
| General Purpose Question Answering (GPQA) | 4.92 |
| Multimodal Understanding and Reasoning (MUSR) | 7.53 |
| Massive Multitask Language Understanding (MMLU-PRO) | 18.45 |

Comments
No comments yet. Be the first to comment!
Leave a Comment