Zephyr 141B - Model Details

Zephyr 141B is a large language model developed by Huggingface, a company known for its contributions to the AI community. This model features 141 billion parameters, making it one of the most powerful variants in the Zephyr series. It is released under the MIT License and the Apache License 2.0, offering flexibility for various applications. The Zephyr models are specifically designed as fine-tuned assistants, with sizes ranging from 7B to 141B parameters to cater to different computational needs.
Description of Zephyr 141B
Zephyr 141B-A39B is a fine-tuned large language model based on mistral-community/Mixtral-8x22B-v0.1, trained using Odds Ratio Preference Optimization (ORPO) with 7,000 instances over 1.3 hours on 4 nodes equipped with 8 H100 GPUs each. It features 141 billion total parameters and 39 billion active parameters, making it highly efficient for complex tasks. The model was developed through collaboration between Argilla, KAIST, and Hugging Face, and its training data combines publicly available sources with synthetic datasets to enhance versatility and performance.
Parameters & Context Length of Zephyr 141B
Zephyr 141B is a large language model with 141 billion parameters, placing it in the category of very large models that excel at complex tasks but require significant computational resources. Its context length of 64,000 tokens allows it to process and generate long-form content effectively, though this capability demands substantial memory and processing power. The model's high parameter count and extended context length make it suitable for advanced applications such as detailed text analysis, multi-turn conversations, and handling extensive documents, but they also necessitate optimized infrastructure for deployment.
- Name: Zephyr 141B
- Parameter Size: 141B
- Context Length: 64k
- Implications: Very large models for complex tasks, long context for extended text processing.
Possible Intended Uses of Zephyr 141B
Zephyr 141B is a large language model with potential applications in areas such as answering questions, coding assistance, mathematical problem-solving, and logical reasoning. These possible uses could involve tasks requiring deep analysis, structured thinking, or technical expertise, but they remain speculative and require further exploration. The model’s design suggests it might support complex queries or generate detailed explanations, though its effectiveness in specific scenarios would depend on factors like training data, fine-tuning, and real-world implementation. While these possible uses highlight its versatility, they should be approached with caution and validated through rigorous testing.
- answering questions
- coding assistance
- mathematical problem-solving
- logical reasoning
Possible Applications of Zephyr 141B
Zephyr 141B is a large-scale language model that could potentially support applications such as answering complex questions, providing coding assistance, solving mathematical problems, and enhancing logical reasoning tasks. These possible uses might benefit from the model’s extensive parameter count and advanced training, but they remain speculative and require careful validation. The model’s capabilities could be explored in scenarios involving detailed analysis or structured problem-solving, though further research is necessary to confirm their viability. Each possible application would need thorough evaluation to ensure alignment with specific requirements and constraints.
- answering complex questions
- providing coding assistance
- solving mathematical problems
- enhancing logical reasoning tasks
Quantized Versions & Hardware Requirements of Zephyr 141B
Zephyr 141B’s medium q4 version, which balances precision and performance, likely requires a GPU with at least 20GB VRAM for models up to 12B parameters, though exact requirements depend on the specific implementation and workload. This version may reduce memory usage compared to higher-precision formats like fp16, making it more accessible for mid-range hardware. However, these are possible estimates and should be verified against the model’s documentation and testing.
- fp16
- q2
- q3
- q4
- q5
- q6
- q8
Conclusion
Zephyr 141B is a large language model with 141 billion parameters and a 64,000-token context length, designed for complex tasks requiring extensive reasoning and long-text processing. It was developed through collaboration between Argilla, KAIST, and Hugging Face, leveraging advanced training techniques and diverse datasets to enhance its versatility and performance.
References
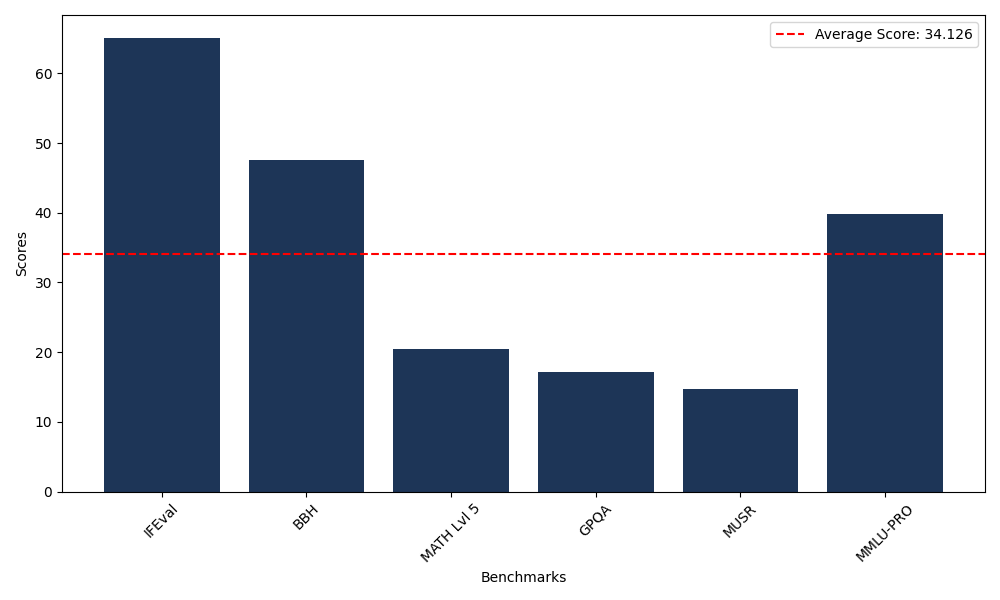
Benchmarks
| Benchmark Name | Score |
|---|---|
| Instruction Following Evaluation (IFEval) | 65.11 |
| Big Bench Hard (BBH) | 47.50 |
| Mathematical Reasoning Test (MATH Lvl 5) | 20.47 |
| General Purpose Question Answering (GPQA) | 17.11 |
| Multimodal Understanding and Reasoning (MUSR) | 14.72 |
| Massive Multitask Language Understanding (MMLU-PRO) | 39.85 |

Comments
No comments yet. Be the first to comment!
Leave a Comment